

Things are heating up


Flatpak

I ordered some furniture for my balcony some months ago, and today it arrived. It’s a small balcony, so I thought some small chairs would make sense…
The shipping company said they were going to be delivered in one 47kg package:
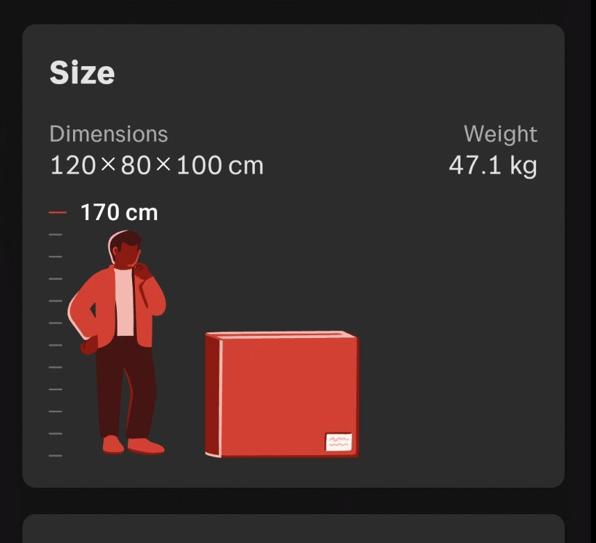
And I got heart palpitations, because I hadn’t ordered carry-stuff-up-all-the-stairs service, and how on earth could two small chairs and a small table be 47kg!?
It turned out they’d just strapped the three curiously, but efficiently packaged things onto a big wooden pallet, and the delivery guys fortunately took that thing with them.

Which left me with this IQ test — how do I get those black metal tabs onto the rounded leg section of the table? D’oh! That’s not how it works… rounded things go on the bottom, not the top. Hah! I’m a genius! It only took me *mumble* minutes to figure that out!

Et voilà! Now I can sit out on the balcony like a proper French man, smoking cigarettes and drinking coffee for breakfast while reading Libération!
(I just have to start smoking and drinking coffee first.)

I suddenly remembered that I had bought a battery powered reading lamp some years back… perfect for reading at midnight.
Finally a place I can read performatively in the privacy of my own home.

Well, the temperature did drop below 22C last night…


If you were this t-shirt, what would you be trying to say?

Got it in the mail today, and I have no recollection of buying it… It’s too large for me, and I can’t make out what the text is saying at all.
Hulp!