
The other day, I started idly wondering how much work it would be to collect the data from all my movie blog posts and then, like, do something with it. Something frivolous. On the movie blog I’ve got this thing, which has a kind of stark quality to it, but I’ve been blogging more about movies on this blog…
My “series” blog posts usually follow some sort of template, so surely it would be easy enough to write some code to parse those, and then make something fun and useless? Like… more overviews… and pages for directors… and… I dunno? Stuff?
That surely wouldn’t take more than a couple of hours of typing, right?
Right?
Reader, it took more than a couple hours of typing.

But now there’s results.
The main problem was that the information (director’s name, IMDB code, movie posters, etc) is partially available from many sources, so it’s a matter of smushing it all together. But no matter how much you code (the Emacs Lisp file for the conversion/HTML generation is at 1,500 lines now), there will inevitably be corner cases that have to be identified and then (semi-)manually corrected.
So I spent way too much time on this, but it’s been kinda fun, anyway. For the “web frontend”, I had ChatGPT code up the required Javascript to do image preloading/animation/etc — it’s the kind of thing I’ve done before many a time manually, but this time around, the “screenshots” are a mixture of jpegs, animated GIF and MP4 snippets, and I didn’t really want to bother with getting the corner cases right myself. I can feel my brain atrophying as we speak.

There’s just so many details when you get into it… like I found that I wanted to weed out (in some contexts) screenshots that have subtitles, and ChatGPT made me a Python script to do that, after poking at it a bit and giving it several examples. It works so-so.
(Hm… Let’s try Claude with the same question. … OK, it came up with a script that’s a fraction of the length, works faster, and is more accurate. Lesson learned — it’s Claude for me from now on.)

And I mainly had posters for things that I had bought on DVD, so I had to poke around more and see why my imdb interface had stopped working for that bit. It turns out that Amazon has made the WAF even tighter — it’s almost impossible to scrape now with a headless Chrome, so I had to allow it to pop on the screen when fetching movie posters… That just goes to show how selfish and solipsistic those guys are. They’re not thinking about my needs! My totally normal behaviour of downloading 1K movie posters! They’re such narcissists!
So this is the main entry, I guess. While futzing around with the layout, I was reminded of what the Windows Phone 8 one looked like — not the tiles themselves, but how the layout was designed for scrolling, with boxes often being shown cut off. So I did that:

And for extra annoyance, I bound the pagedown/up keys to scroll horizontally! It’s gruesome! *twirls stache* *ouch* That’s my lip! Careful!
ChatGPT was also helpful in its customary LLM way when making a country code to country name mapping file. It’s mostly the standard two letter codes, but there’s also IMDB-specific codes for countries that no longer exists, like East Germany. After it telling me a couple times that I really wanted something else (and more complicated), it coughed it up… but randomly forgot two countries (Dominica and Macedonia).
I guess I shouldn’t complain — it does save a lot of time, but it’s just so odd what kind of things it fails at…
The box I had for the list of countries was just too small, so either I had to think of a new layout, or… I could ask ChatGPT for å JS snippet to emulate a movie end title? Easy choice!
Since I’ve got all this data, I might as well do some stats.
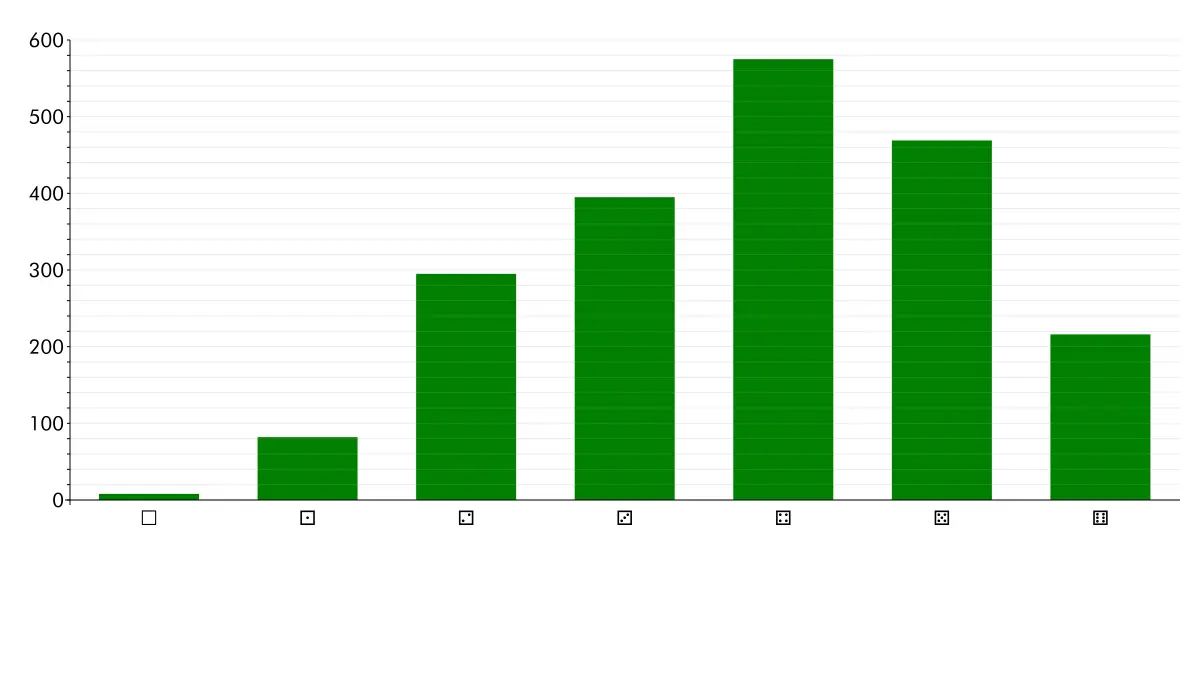
Heh… looking over individual scores, they do look a bit eccentric. But, like, I’m giving a score for “what it is”. For instance, the lowest-rated Chantal Akerman film is Sud, which I gave a three. That movie is, objectively speaking, much, much better than any super-hero movie, so logically speaking I should be giving all super-hero movies a one or a two. But that’d be boring, so I have a different scale for different kinds of movies. “This is pretty good, for what kind of movie it is”, like.
Does everybody do that? I don’t know what the Letterboxd crowd does…
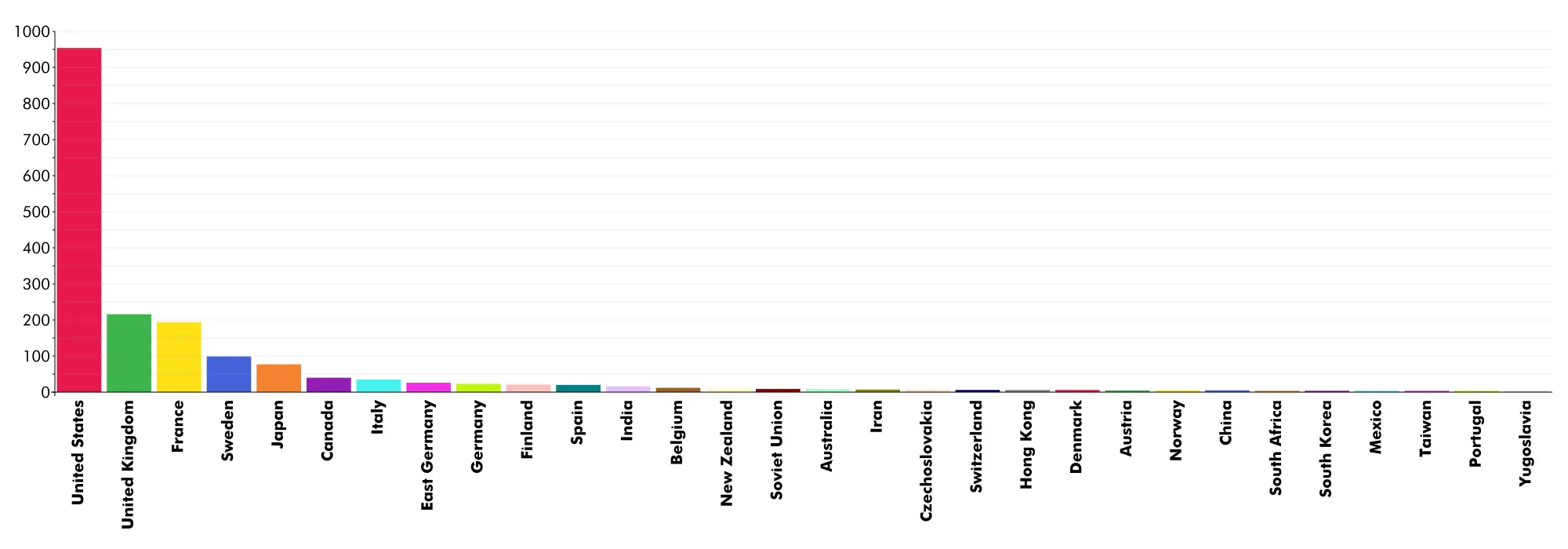
Not a lot of surprises on the country chart… lots of western…
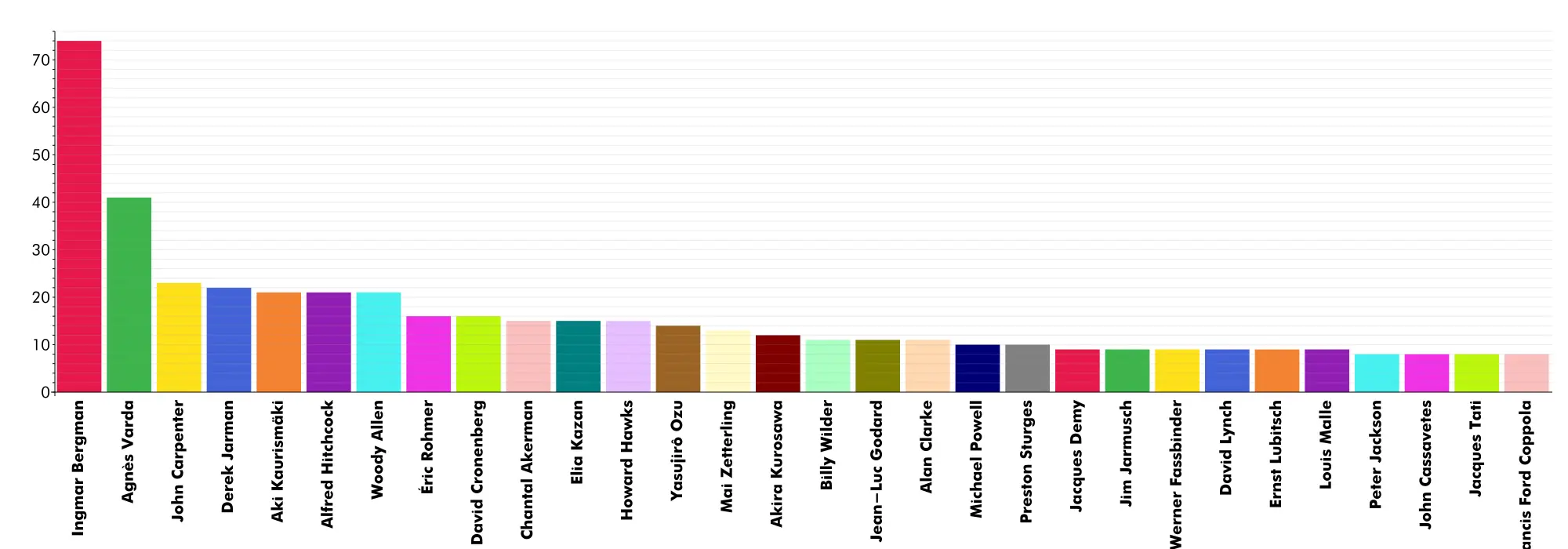
Good ol’ Ingmar wins.
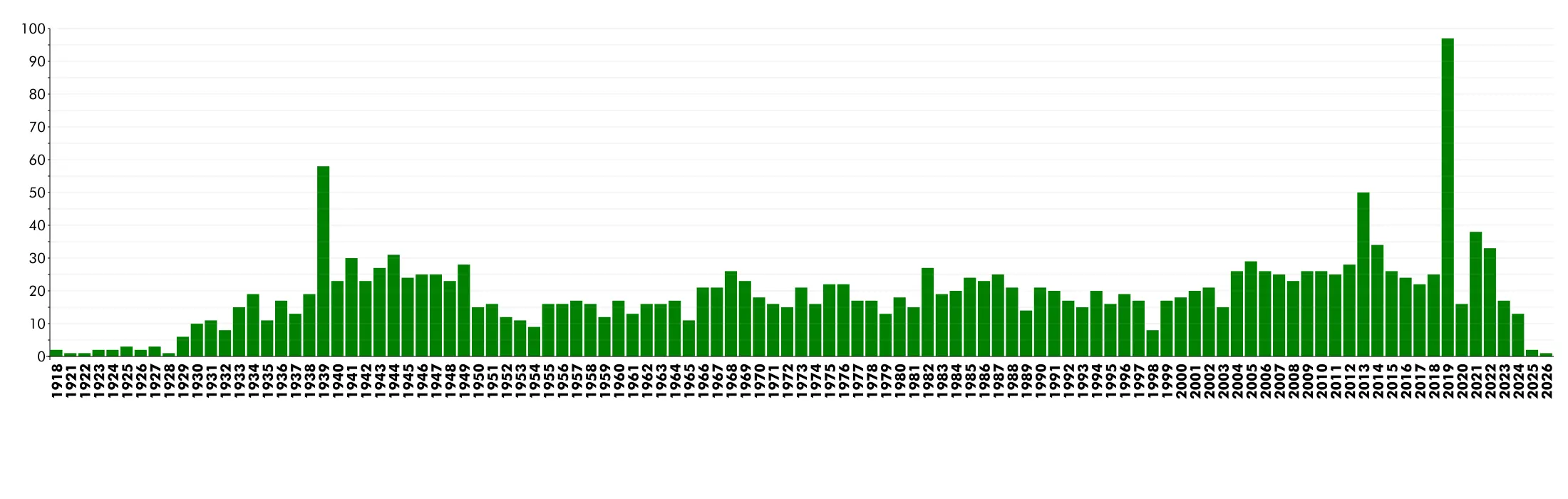
Wow, 2019 must have been a good year for movies! Or perhaps there’s a different reason…
Anyway. That was a lot of typing for an end result that isn’t, strictly speaking, useful…