Is this good or bad?
OK, let me explain.
I google with site:ingebrigtsen.no a lot because I use this blog as a way to externalise my memory. (I’m forgetful.) Half a year ago, I noticed that I was getting weird results. After fixing that problem, I eventually signed up for the Google Search Console to see whether anything else should be fixed (I mean, just because of curiosity on my part, I guess).
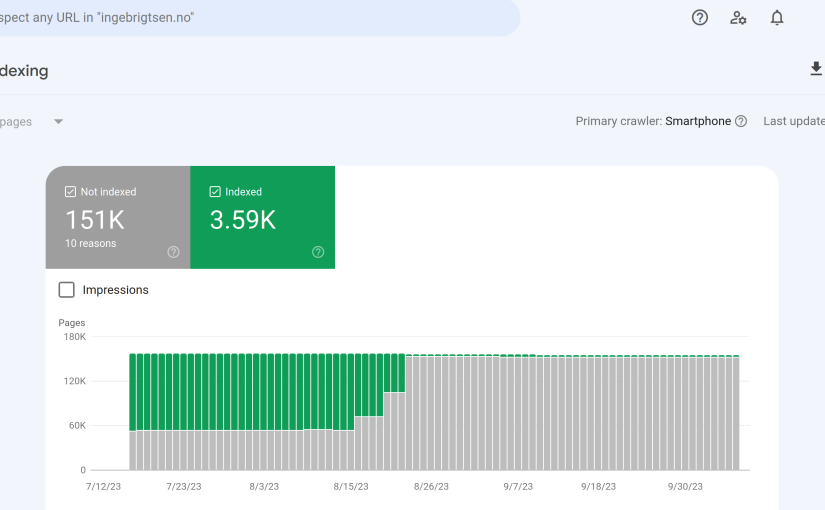
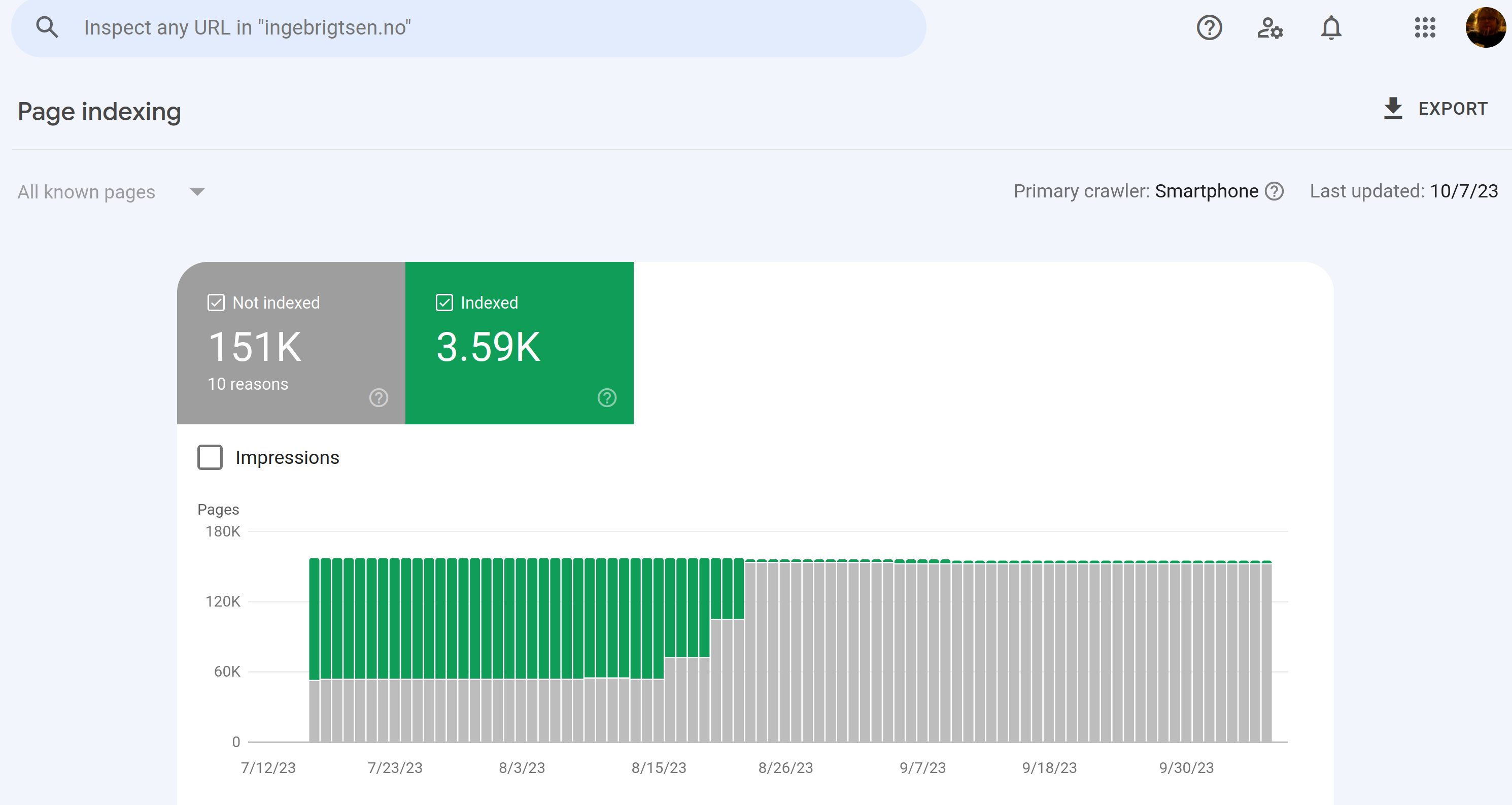
My first question was: I have 151K pages!? Of which 60K aren’t indexed?
There’s about 4K “real” pages in this domain, spread over two blogs, basically. But since this is WordPress, there’s a lot of URL duplication. Every page has a /feed/ page, and there’s a “short code” version of every URL, and there’s another “short code” that comes from WordPress.com, and probably an AMP URL, and and… I’m forgetting a lot.
But now Google is saying there’s 151K pages not indexed, and 3.6K pages that are indexed. The latter is fewer than the actual number of pages.
So:
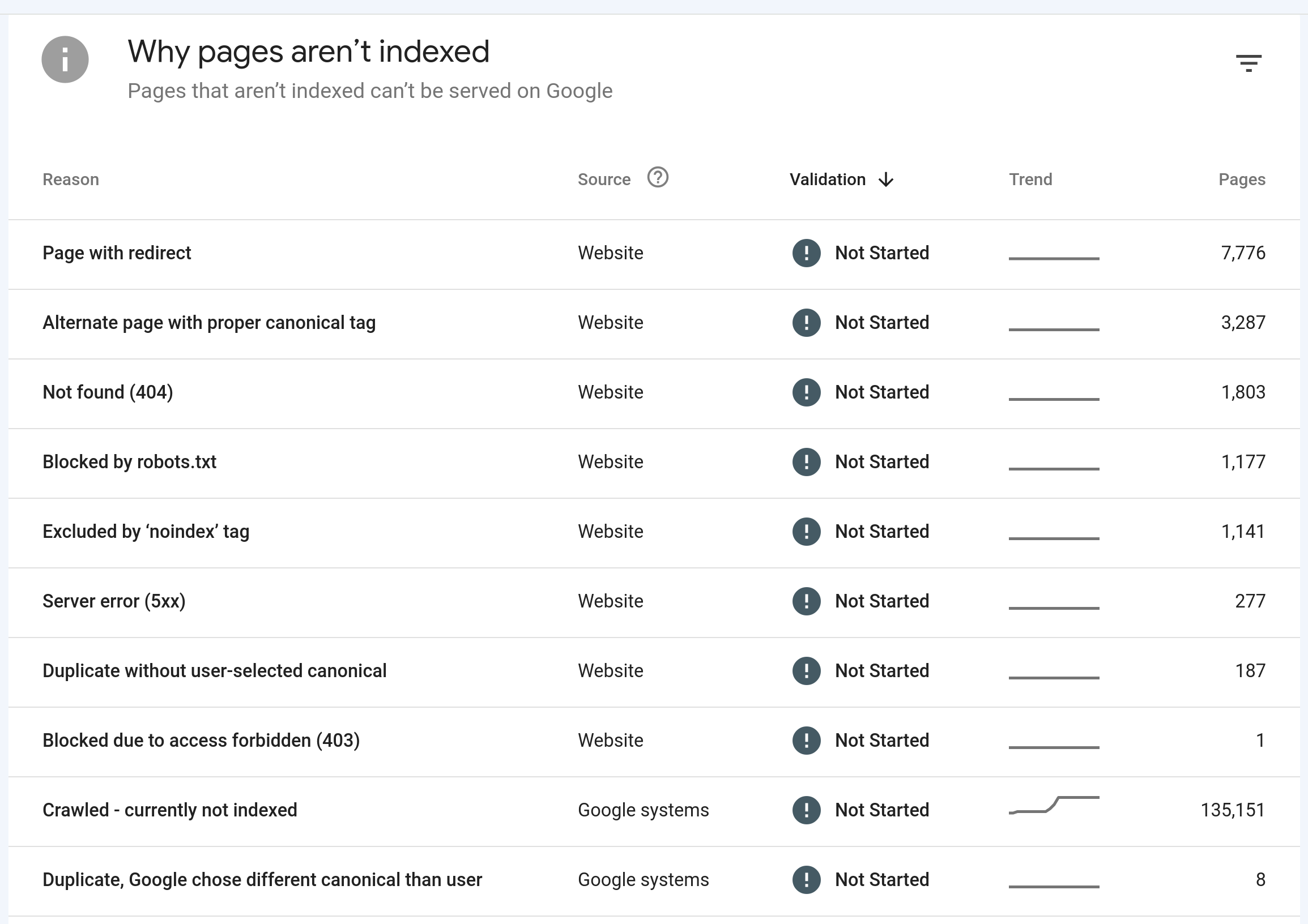
So… that all looks sensible, except the “crawled — currently not indexed”, which is what’s grown, I think. Yeah:
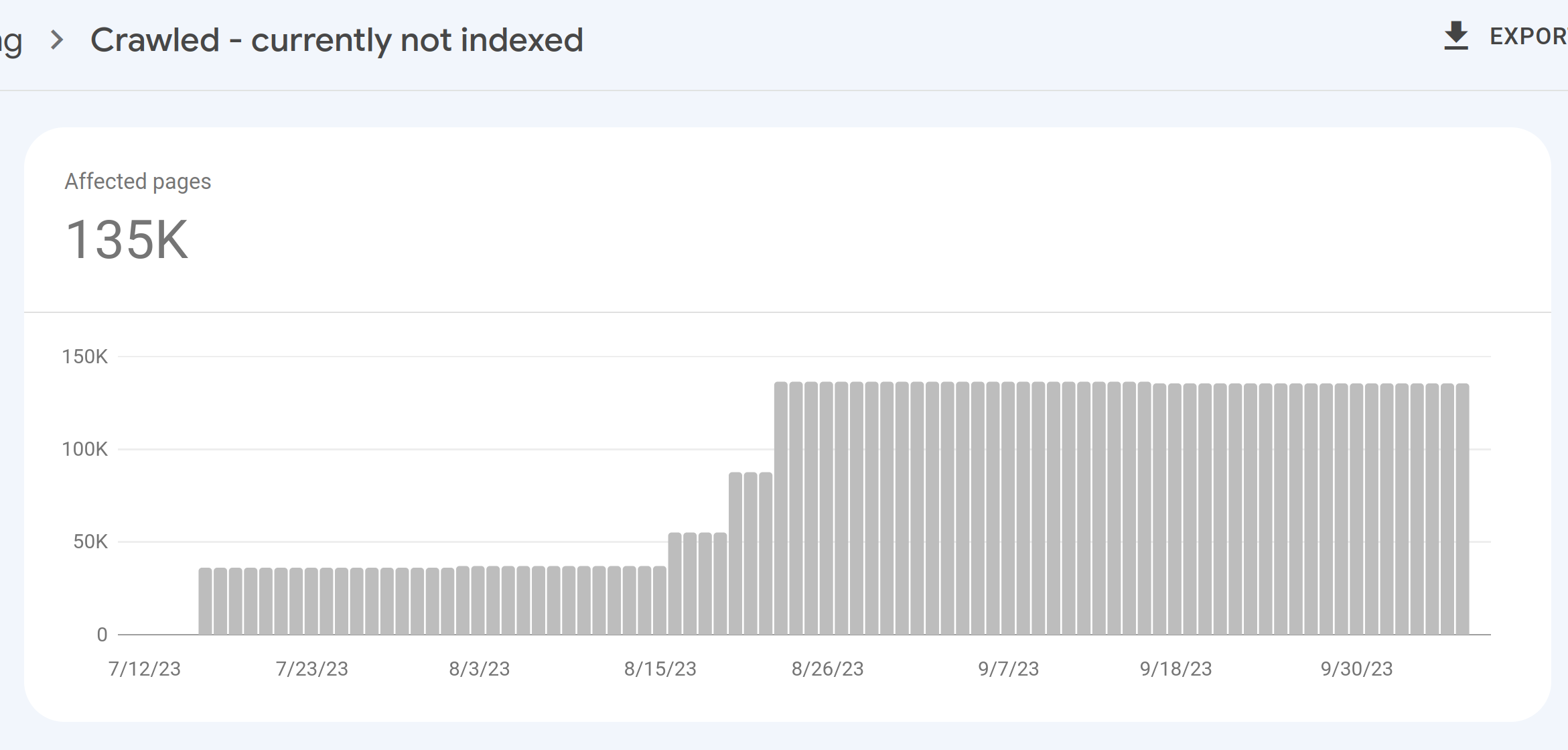
Yup.
So what are these URLs?
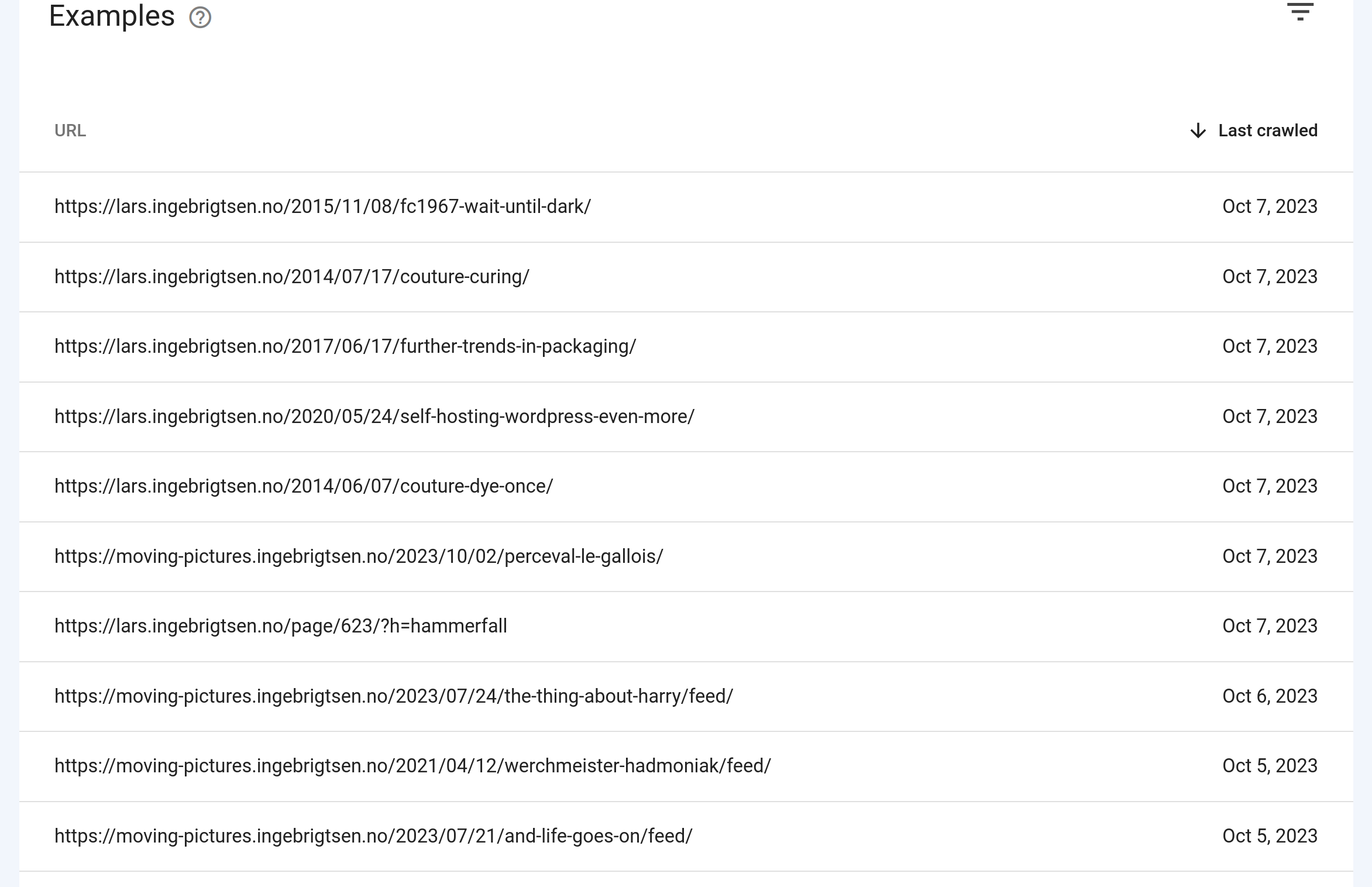
OK, there’s a couple /feed/ pages, which is nice, but there also seems to be some actual blog posts? So let’s google for one of them:
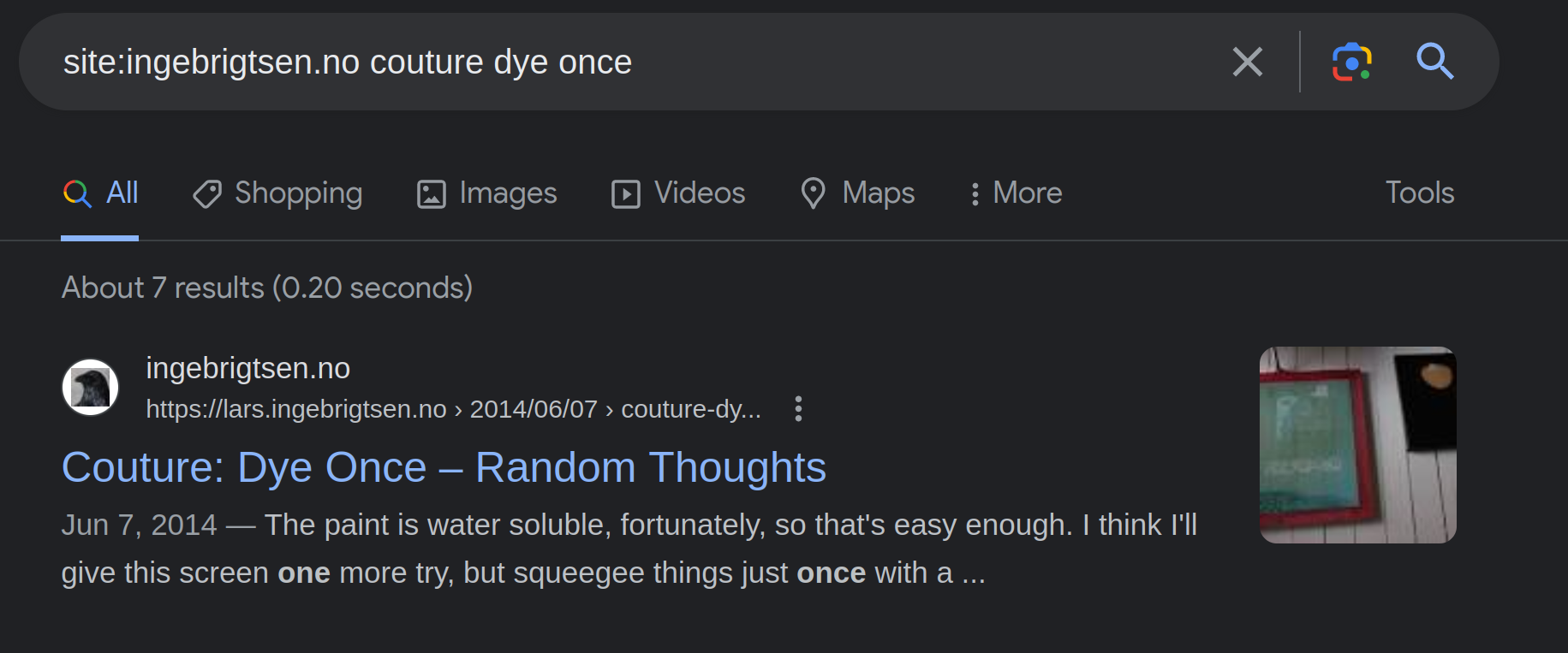
And… it’s there!?
*sigh*
So is the Google Search Console just nonsense? The only help the help pages have to offer on this issue is:

I mean, none of this matters very much. I’m just curious.
And no, I’m not really expecting Google to index every silly little blog in existence — the search engine is theirs, and they are entitled to do whatever they want. But it’s a nice, convenient service when it works.
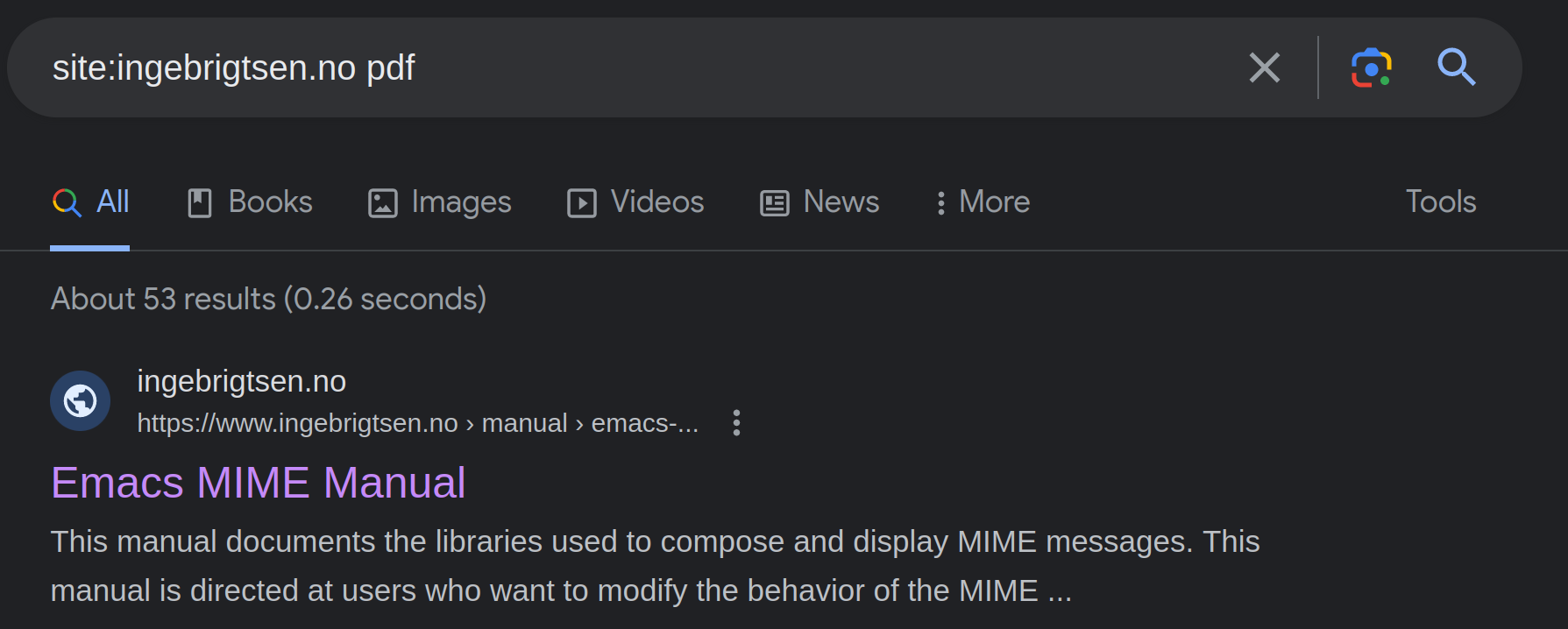
And while I’m whingeing about the Google Search Console, I might as well whine about this mystery, too: Google seems to think that all of the Gnus manuals that exist on the gnus.org domain exist under www.ingebrigtsen.no, too. They’re both hosted on the same web server, so they resolve to the same address. So I thought this might be due to a misconfiguration on the server — it wouldn’t be the first time, since Apache amusingly defaults to using the “default” directories when you forget to set up domains properly.

But clicking on that gives you the expected result — that the document doesn’t exist.
Anybody have any idea what’s up here?