I added event descriptions to my Concerts in Oslo a few months back. It mostly worked kinda OK, but it’s using heuristics to find out what “the text” is, so it sometimes includes less-than-useful information.
In particular, those fucking “YES IT KNOW IT”S A FUCKING COOKIE!” texts that all fucking web sites slather their pages with now fucking get in the way, because those texts are often a significant portion of the text on any random page. (Fucking.)
But I added filtering for the those bits, and things looked fine.
Yesterday I was told that all Facebook events are basically nothing but that cookie warning (in Norwegian), and that’s because the Facebook event pages now contain nothing but that text, plus some scaffolding to load the rest as JSON:
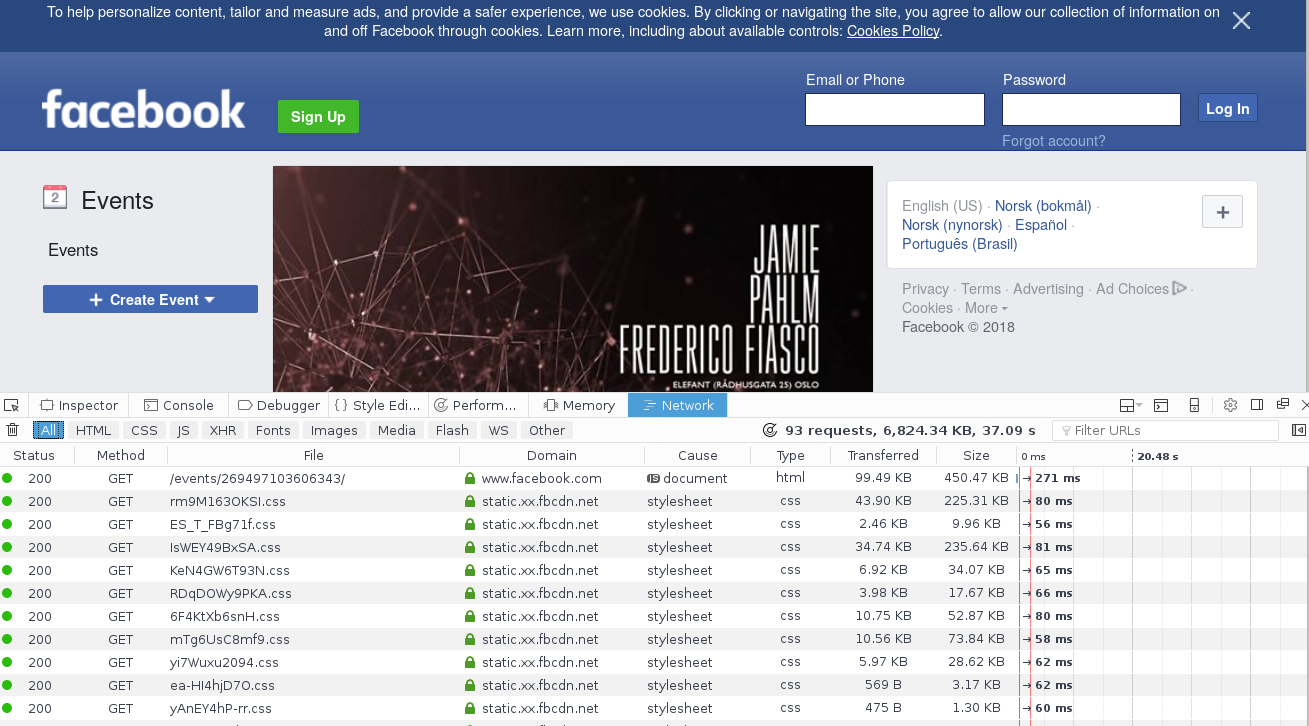
To build the Facebook event page, about 85 HTTP calls are done and 6MB worth of data is loaded.
I contemplated reverse-engineering the calls to get the event description via the graphql calls (since Facebook has closed all access to public events via their API), but then it struck me: The browser is showing me all this data, so perhaps I could just point a headless browser towards the site, and then ask it to dump its DOM, and then I can parse that?
I know, it’s probably a common technique, but I’d just not considered it at all. A mental block of some kind, I guess. I’m so embarrassed. Of course, it now takes 1000x longer to scrape a Facebook event than something that just puts the event descriptions in the HTML, but whatevs. That’s what you have caches for.
I’m using PhantomJS, and it seems to work well (even if development has been discontinued). PhantomJS is so easy and pleasant to work with that I think I’ll try to stick with it until it disappears completely. Is there another headless browser that’s as good? All the other ones I’ve seen are more… enterprisey.
Chrome and Firefox support headless mode now, so combine that with a suitable library and you’re good to go. There’s plenty in JS, but I’ve also seen things like a pure Clojure implementation of the Webdriver protocol for automation.