Yesterday, there was an intriguing announcement about an inference card that’s, er, basically 100x faster than ChatGPT. As a hackernews said:
I often remind people two orders of quantitative change is a qualitative change.
Which is true — speed matters. So I went to check out chat Jimmy, and gave it my standard LLM question:

And started looking for those books… which mostly were hallucinated. Very 2023. When I finally scrolled down to ask “er, what?”, I saw:

Oh.

Oh.

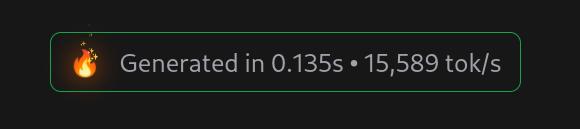
OK, I get it — it’s llama 8B, and it has no particular knowledge of anything, so all it can do is output fantasies. You need to hook it up to something that knows something about the area you’re interested in to get it to do something useful. And it is indeed very fast:
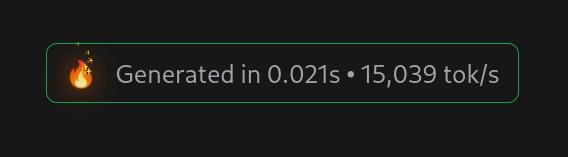
So this is not really interesting in and of itself — this is the expected result, but it just lines up with, basically, every single time I’ve tried to use an LLM for something useful after reading some hype. My previous attempt was yesterday, when I hooked up an LLM to a RAG that had ingested 1 million fanzine pages about comics, and the results were pretty unimpressive — it’s no more than a really bad search engine that’s able to form English-sounding sentences.
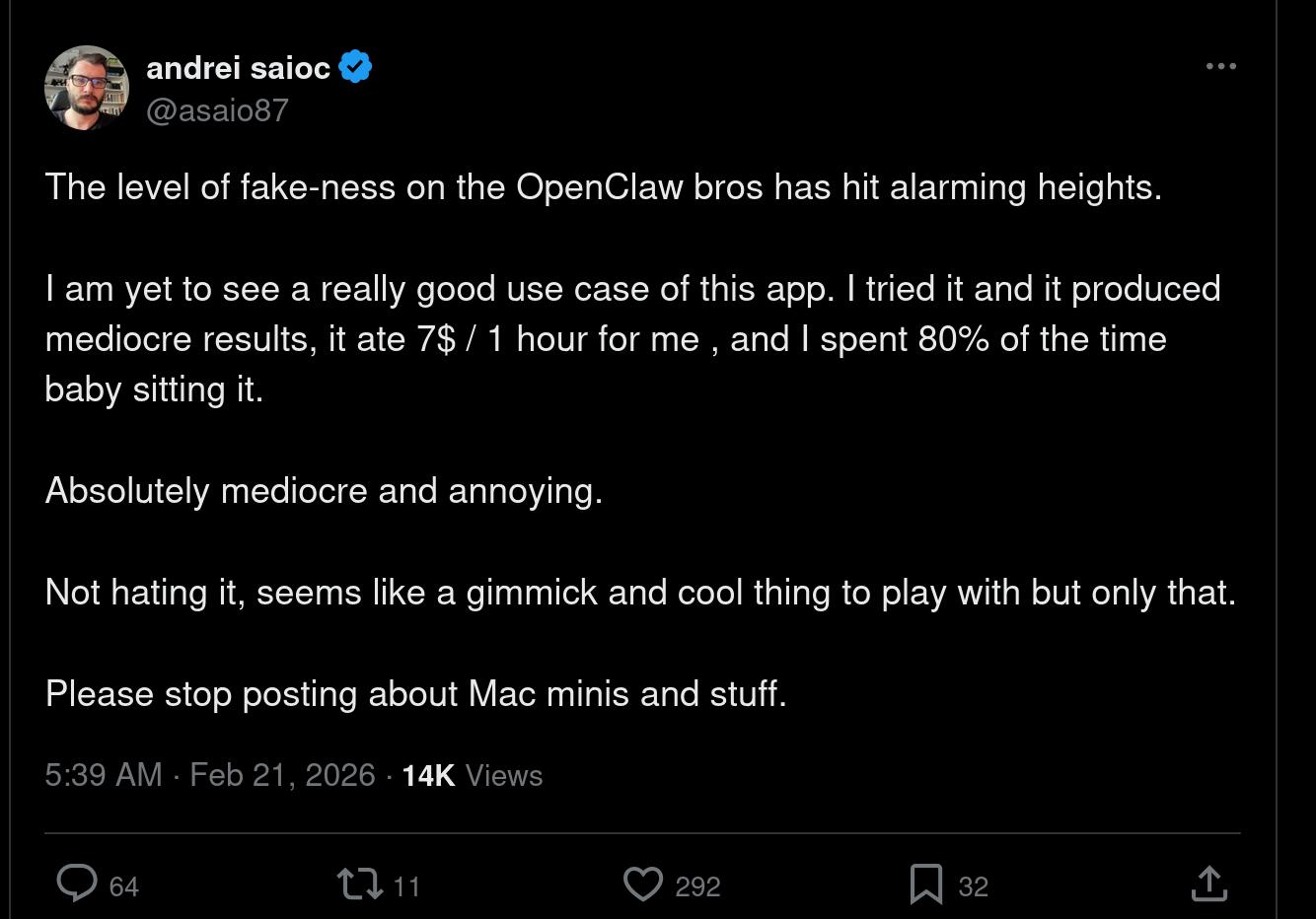
It’s just… I don’t think I’ve ever seen such a disconnect between the relentless hype — not just on Twitter, but in the press, and from every CEO of every major company: LLMs aren’t just going to be transformative in the future, they’re absolutely essential to use now, right now, at this very minute… and then I try to use them for something, and what I end up with is basically an unreliable toy. And one that’s very expensive to use.
(I had one LLM success story I used to tell so that I wouldn’t sound like a luddite fighting against windmills: “I had a 200 line Javascript package that used jQuery, and I asked ChatGPT to rewrite it to use standard Javascript, and it worked on the first try!” But then, after being in production for some weeks, I noticed that I wasn’t getting one particular (rarer) event… and looked at the code, and saw that it mostly worked (for the main event) by accident, and not at all for the side case.)
(OK, OK, LLMs are really good for OCR, I’ll give them that…)
There is pushback like the above, but it’s still mind-blowing how people are letting hucksters like this set the agenda:
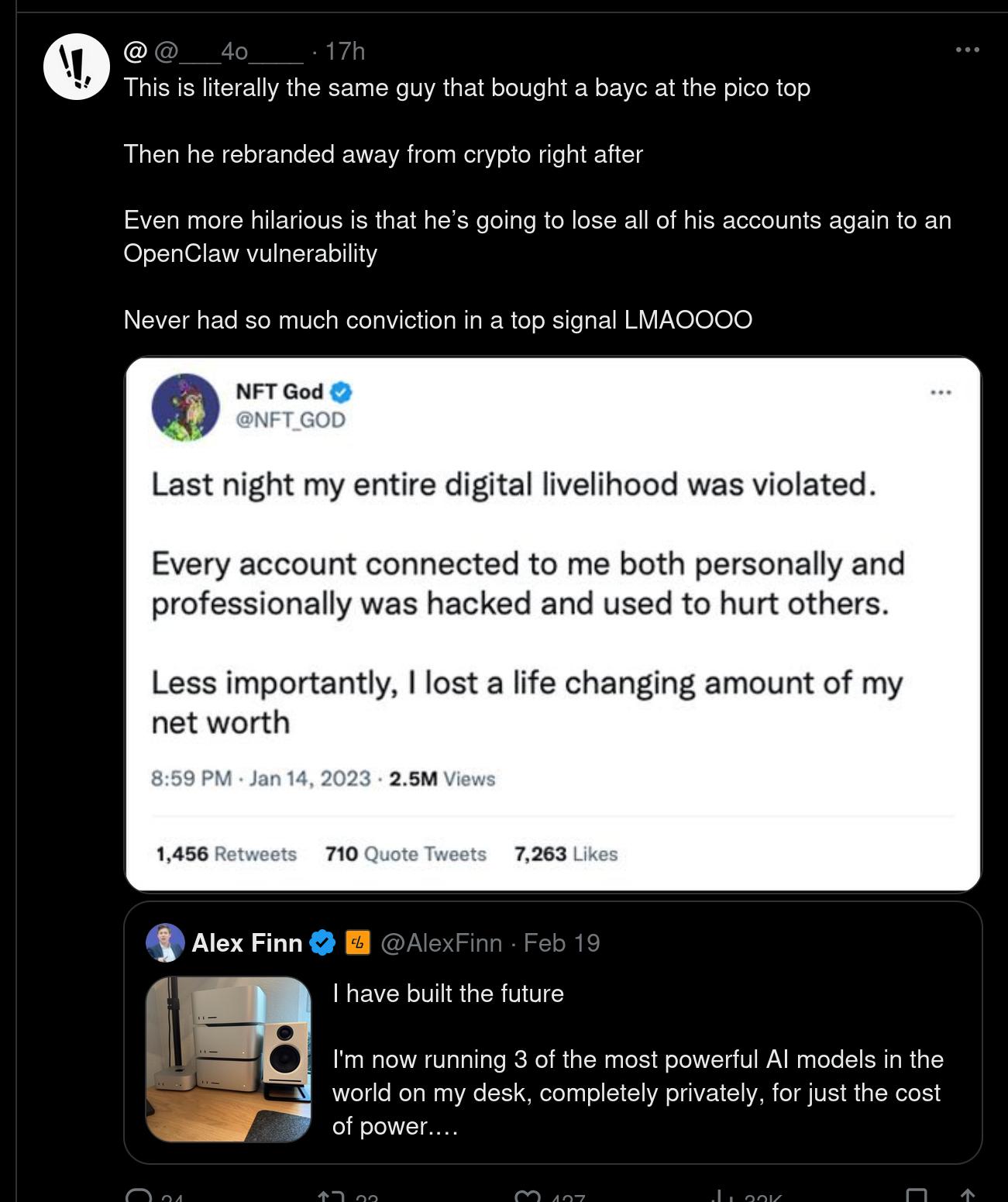
People are buying Mac Minis so that they can run something that queries the Anthropic API? Whyyye!? (And if they’re running local models, they need a beefier GPU.) But it makes total sense that it’s the people who lost their money on NFTs that are spearheading this revolution.
At least we get some comedy out of all of this.
It’s not unlikely that these technologies will be actually useful and more reliable at some point in the future. Q1 2026 is not that time, and there is still no hurry to jump on any bandwagon: Experimenting with it now is a waste of time and money.
There’s no hurry. You’re not missing out on anything. Relax.
If (or when) this technology matures, you can start using it then. Isn’t that the hook here? This stuff is going to be so intelligent that you don’t have to know anything about anything? Right? So you don’t have to start learning now.
> I don’t think I’ve ever seen such a disconnect between the relentless hype — not just on Twitter, but in the press, and from every CEO of every major company: LLMs aren’t just going to be transformative in the future, they’re absolutely essential to use now, right now, at this very minute…
Tell me about it!
If you do not work in a company where the leadership has swallowed the “You all Must use AI or we will be left behind completely”-pill, consider yourself lucky…