When writing blog posts, I use ewp, an Emacs package to administrate WordPress. It offers an editing mode based on the revolutionary idea of just writing HTML.
Everything is cyclical in computing, so people move between writing things in raw HTML and using arcane and unholy systems, mostly based on some Markdown dialect. I understand the frustrations: It feels like there should be something that’s less annoying than using some WYSIWYG tool that invariably freaks out and ruins your post, or typing all that annoying HTML yourself, or using Markdown and then having to have some kind of build step.
In my opinion, Markdown is fine for writing README files, but if you’re writing blog posts, it just gets in the way. A blog post is mainly just paragraphs like the one I’m typing (and you’re reading) now, which is just text with no markup. Or there’s some slight formatting for emphasis or the like, but honestly, there’s not much difference between the HTML and Markdown versions for that.
Markdown is nice for headings and code snippets, but doesn’t really offer much useful for blog posts. And the things that blog posts need, which is images/screenshots and links: Markdown doesn’t help you much there.

Is that really better than the HTML version? And what, then if you need more stuff in the link?

It just gets worse and worse — what if you need to put more data into the links? The nice thing about HTML is that it’s well-formed and not very hacky — the more cruft you add to the HTML, the more unreadable it gets — but linearly. Markdown makes the easy stuff trivial, and the difficult stuff worse. (Here’s there the Greek chorus of “but you can just write HTML in Markdown” comes in, but that’s worse than just writing HTML in the first place.)
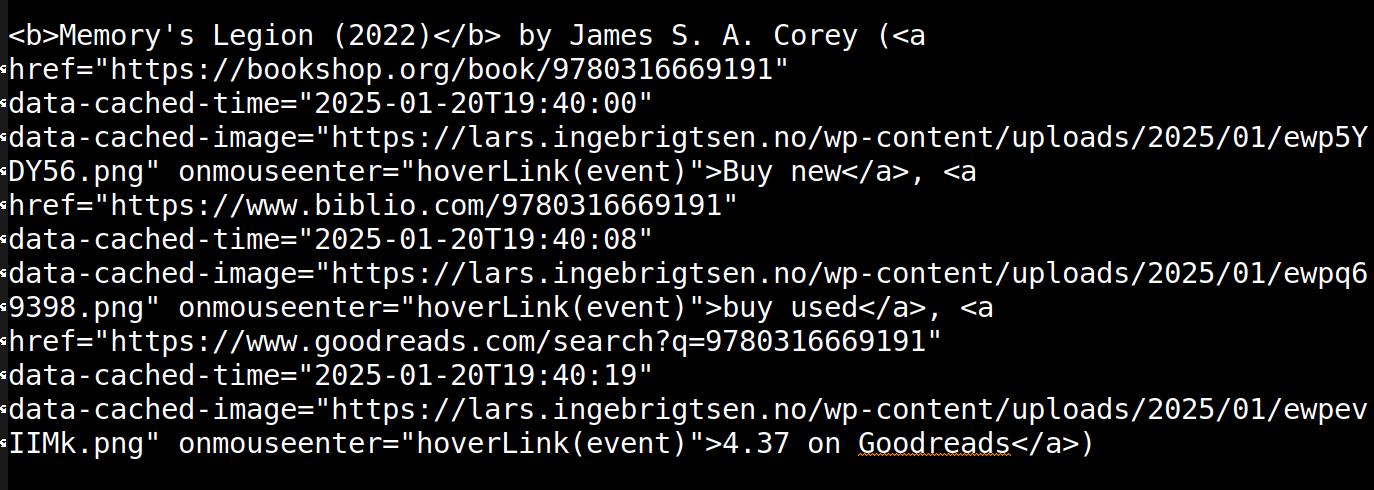
So: I write HTML, and Emacs takes care of displaying the images I’m linking to, so a blog post looks like this while I’m writing:
(To digress: I’ve noted over the years the many, many posts on HackerNews about statically generated blogs, and people have more fun spending time tinkering with their setups than actually writing blog posts, and that’s fine. But I’ve noted that virtually none of these systems have a mechanism for dealing with images in a natural way — because that’s just kinda hard. The nearest you get is “then you just create an S3 bucket and put the image there, and then you go to the AWS console to get the URL, and then you paste that into the Markdown here. See? PROBLEM SOLVED!!!” That’s why blog posts from all these people (random example) are almost always just walls of text.)
Anyway, here’s my problem:
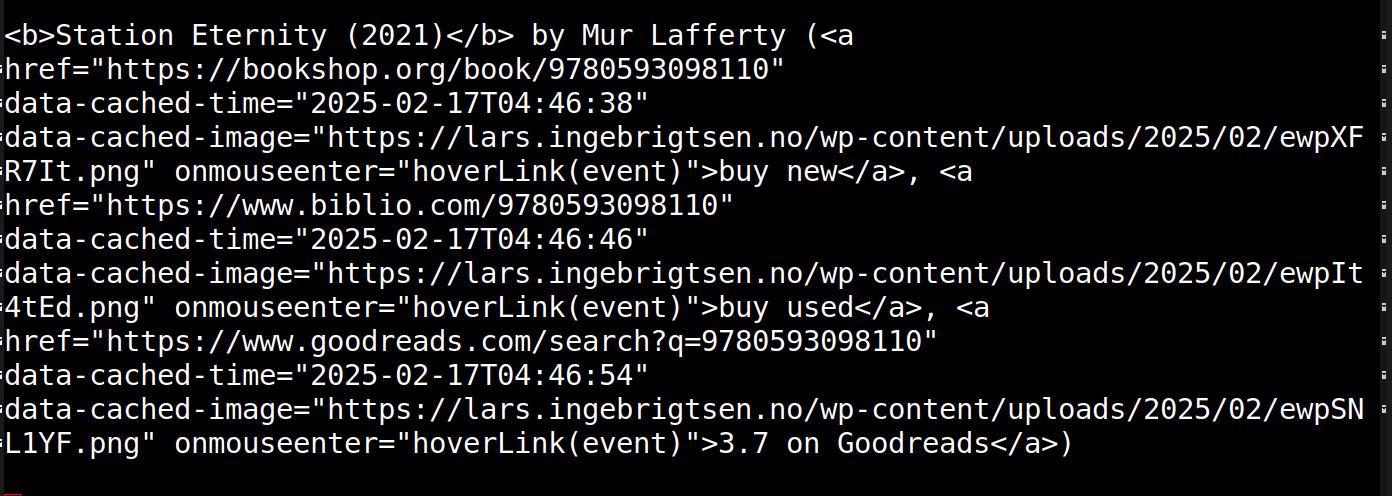
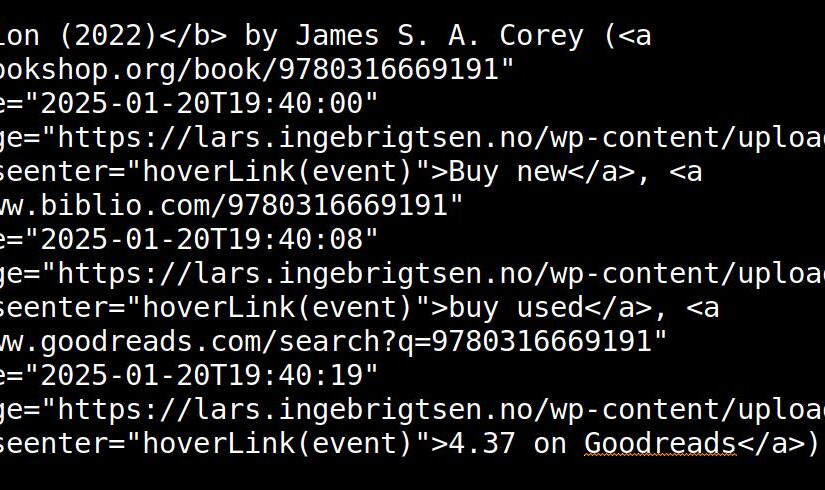
YIKES! WHAT THE… Yes, I hear you.
To protect myself a bit against link rot, ewp screenshots everything I link to automatically. So on the blog, you can just hover over a link to see (and read, if you want to) what I was linking to at the time, and that will survive as long as my blog survives (while most of the things I’m linking to disappear, apparently).
But that means that I have to stash that data somewhere, and I stashed it in the links, which means that the HTML then becomes unreadable.
This is Emacs, however. What about just hiding all that junk?
![]()
Yes, that’s the same paragraph with the links hidden. And if I want to edit the links themselves, I can just hit TAB on the bracket:

And TAB again to hide:

Note that the links and stuff are still present in the Emacs buffer, so the normal Emacs autosave functions work perfectly, and there’s no danger of losing any data.
Similarly, the image HTML in WordPress can be pretty messy:

Because images have extra classes with their IDs, and you can click on images to get the full sizes, so they’re (almost always) wrapped in an <a>. Now, when writing articles, Emacs displays the images instead of the HTML, so we don’t see all that cruft anyway, but when editing image heavy articles, it can take some time to fetch the images, and we don’t want to be staring at junk like that while waiting for the images to arrive.
So let’s hide them like this:

And TAB can be used to cycle through the three different forms:
I think that looks kinda pleasant to work with…
Anyway, I think that’s as far as I want to go with hiding the HTML-ness of things. I mean, the temptation here is to start going in a more WYSIWYG direction, and translating <b>…</b> into bold text and all that sort of stuff, but… I’m more comfortable just looking at the tags?
So there you go: In the “just write HTML/no don’t write HTML” wars, I’m on “just write HTML but have the editor hide some of the worst of the cruft” tip.
I agree with you about HTML and Markdown, but then the package I was using to write html in Emacs (psgml) disappeared. It looked like the only thing with enough support to be sure to stay maintained was org-mode, so eventually I bit the dust and started writing posts in that. (I guess it’s a dialect of markdown, but not close enough to just use it without a build step.) I agree completely about it being no help at all with images.
I am using whatever is the built-in mode for HTML these days, and it works pretty good. It has some shortcuts for text formatting, and you can surround an active region with tags, add links with a special command. It’s pretty ergonomic.
My needs are very basic. But I don’t think learning the shortcuts for that mode can be more complicated than dealing with the org behemoth and a conversion step.
Not that you would change your workflow now…and if you are already into the org sub-ecosystem, then it isn’t as daunting, I guess 🙂
Pingback: hillenius.net