

The GPU-assisted OCR run for kwakk.info has now finished — it took about three weeks to chew through 10,000 fanzine/magazine issues. So what are the results?
Well, I found that sections with no text would often end up with hallucinated kanji. (Because LLM.) It doesn’t really matter much — you wouldn’t be searching for these things anyway. But if you want to quote a text, it’s annoying if there’s a bunch of kanji in the middle of whatever you’re quoting, so I wondered whether there was a way to filter that junk out.
And there is!

Because surya, the LLM OCR software, assigns a confidence level to every line (and even every character). And “actual text” turns out to have a high confidence — the sentence above has a 99% confidence…
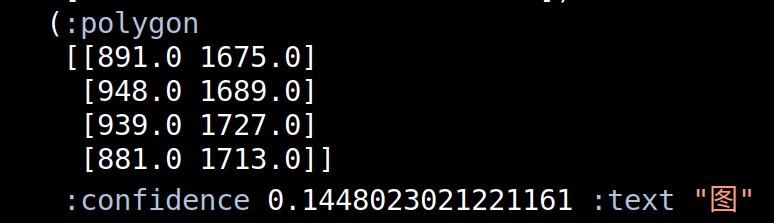
… while surya’s 14% sure about this kanji. (I think that’s way more sure than it should be about something it’s so wrong about, but that’s just me.)
So I just filtered out everything with a confidence level below 60%, and that fixed the vast, vast majority of these hallucinations.
But otherwise… how’s the quality now compared to what it was before? Let’s look at a couple examples. The first is a normal, well-scanned text page from RBCC (Rocket’s Blast & Comicollector):

Should be easy to OCR, right? Here’s the results from the traditional OCR:
And indeed, it looks pretty good. It’s perhaps 90% correct? Although some lines are in the wrong order. But "EC" has become NEC", for instance, and their "New Trend" comics has become their "New Trend W in comics.
So if you want to quote text from this page, you’ll have to spend some time copy-editing it.
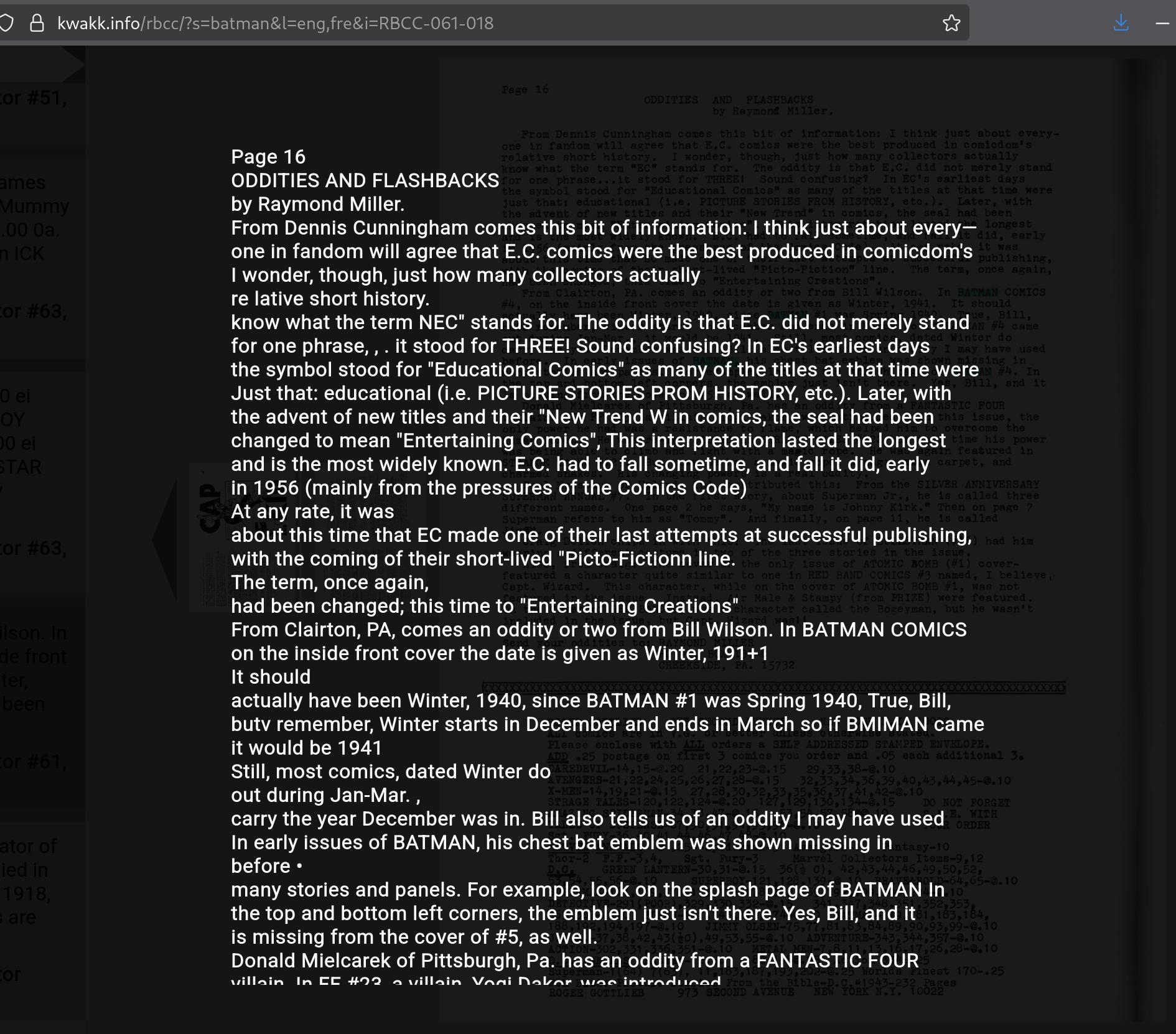
Here’s the results from surya:

First of all, the lines are in correct order. But there’s also a lot fewer word recognition errors — I haven’t counted, but I think this is more than 99% correct? So if you want to quote an article from kwakk.info now, you won’t have to spend the rest of the afternoon doing copy edits.
But what about harder stuff? Here’s another RBCC example, but it’s a much worse scan, and it’s a “catalogue” page, which are just harder to parse in general:

Here’s the results from the traditional OCR:

Uhm… er… well, that resembles line noise — you can’t use that; it would be easier to just transcribe that page by hand than trying to “fix” this by editing.
Here’s the surya output:

It’s pretty good! There’s still errors like MAGAZIKES and Jomen, but it’s mostly correct, as far as I can tell.
So there you go. Quoting text should now require a lot less editing afterwards, and, of course, the search itself should be more precise (and find more instances of whatever you’re searching for than previously).
The GPU has kept my home office nice and warm while it’s been OCR-ing these past weeks, which is also a plus.

And dealing with 4GB JSON files (the surya output is very verbose) has been fun — can’t really parse them normally, but whatevs — Emacs is pretty good at dealing with big files, so I just wrote something to plop them into a buffer and parse them gingerly.
If you see any major oddities, let me know.