


Well, whaddayou know — my post about an obscure en/decoding issue went totally viral yesterday! I had no idea that people were so interested in RFC2045, an email standard from 1996. Just goes to show…
Just kidding!
But I see there was some confusion about some details (mostly due to my unfortunate tendency to (try to) be funny), so I thought I’d bloviate a bit more in case anybody’s still confused. And! A bit about the server problems at the end, too.
OK?
So: Over the past few days, I’d been getting more and more annoyed with threads about the horrific Epstein emails that had been published. I mean, not about the horrificness itself, but because I’m a nerd. I was getting really fed up with all those people, so sure of themselves, declaring that one specific oddness — the presence of = characters sprinkled almost as on random, replacing other characters — were due to OCR artefacts.
Now, I know OCR (I’ve done millions of pages), and let me tell you, sirrah, those are no OCR artefacts.
It was even more annoying when people were incorrecting each other with things like “yeah, you can see that it pops up more often when the letter should have been an h” and so on. NO YOU FOOLS! YOU FOOLS! IT”S QUOTED PRINTABLE!!! *storms out in a huff*
I did see other people point out the quoted printableness of it all, but I didn’t see anybody actually explain the specific oddities we were seeing. If somebody in charge of processing these emails, knowing nothing about email, were seeing “huh, a lot of these lines end with =, let’s just remove those”, you wouldn’t get missing characters. You’d get oddly formatted lines, but in any case, you’d have gotten rid of those equal signs for sure.
So I didn’t post anything, because I didn’t really have a good explanation other than “you’re all wrong! wrong I tells ya!” *stomps foot*
(The other popular hypothesis was that Epstein cleverly inserted = into random words, replacing other characters, because it was some sort of secret code. *sigh*)
But then it came to me… what if it’s not actually continuation handling that has gone wrong here, really? What if it’s that other thing in quoted printable — non-ASCII characters?
I did some googling… and I found somebody had experienced exactly that problem in the wild! 14 years ago! Yes!
So here’s the algorithm I think they used. The algorithm is buggy, but if you’ve dealt with encodings like this before, I think you can see how it ended up like this.
- First you want to fix up continuation lines. You’re working on a Windows machine, or you’re actually reading the RFC (I know, don’t laugh — I know it’s unlikely). A continuation line on a Windows machine is =CRLF. So you write:
(while (search-forward "=\r\n" nil t) (replace-match ""))
(For the code examples, I’m assuming whoever was doing this conversion was using Emacs Lisp, because aren’t everybody? Ahem. Same thing in any language, really.)
The problem here is that you’ve gotten all these files from Gmail, and they’re not a Windows shop — so the line endings are "=\n" instead.
So your first pass over the file does absolutely nothing, but you don’t notice, because then your program hits pass two:
- You look for = followed by two characters. This encodes to one non-ASCII character. (Or octet, really.) Because you know that that’s the only thing left — you’ve already handled all the continuation lines, right? Right? Right. So you delete the two encoding characters, and then you replace the = with the new byte. But you have some sanity checks, of course!
(while (re-search-forward "=\\(..\\)" nil t) (let ((code (match-string 1))) (delete-region (match-beginning 1) (match-end 1)) (when-let ((new-byte (decode-hex code))) (subst-char-in-region (match-beginning 0) (1+ (match-beginning 0)) ?= new-byte))))The sanity check is, unfortunately, that if the thing doesn’t actually decode, you leave the = in place. And in this case, it never decodes, because =\nc is never valid.
I can certainly say that I’ve written code along these lines before, unfortunately.
So there you go. The mystery is why there’s still some =C2 things in there — but I think that can be explained by just having some off-by-one errors. That is, the mails originally had =C2=A0 (which is UTF-8 for NON BREAKING SPACE), and you often see either the =C2 or the =A0 missing, so my guess is that the algo just skipped ahead a bit too much — which would also be a typical error you wouldn’t find while doing some trivial testing under Windows, where your test files wouldn’t be in UTF-8, but in a code page like CP1252, where characters like NON BREAKING SPACE consist of one byte only.
So that’s my er “theory”, based on implementing mail standards for decades, and observing how sloppy people are when approaching this stuff. I mean, the RFCs are usually very straightforward and easy to follow, but people seem to wing it anyway.

Here’s a fun example — you see the character-replaced-by-equals effect you’d get with the algo described above (note ke=ping), but you also have the decode-half-the-non-ASCII-bytes thing — you probably had =C2=B7, which is supposed to be a · (a middle dot character) or something along those lines, but only the second byte has been converted, and not the first. (So you get an invalid character instead.) I don’t really have an explanation for how you’d mess up something like that, but us programmers are good at inventing new methods of doing the wrong thing, aren’t we? (If you have a theory for what the algo looked like, feel free to leave a comment.)
You can also see emails that haven’t been converted at all:

This is just a line-folded raw Quoted-Printable mail: Note the no= te, where neither the equals sign, the line ending nor the following character have been removed. (The undecoded =C2=A0s just decode to NON BREAKING SPACE.)
I’m also slightly curious about whether these email were really multipart/alternative — that is, whether the person preparing these emails for printing just chose the text/plain parts to work on, since that would obviously be less work than to print out the text/html parts? That would also explain why all the images and stuff have gone missing…
Anyway.
How did the viralness go, I hear nobody ask? Well, my post was posted on Hacker News, and I was going “hah, once again, behold my wonderful WordPress installation, which has no problems dealing with any of this stuff; I wonder why so many sites go down when they land on Hacker News (I’ve been there several times and I’ve never seen a load over 0.5), all those other people must be amateurs. Not to mention those smug static site generator people… So unnecessary…”
Aaaargh! WHAT! WHAT”S HAPPENING! THE SITE IS DOWN!!!
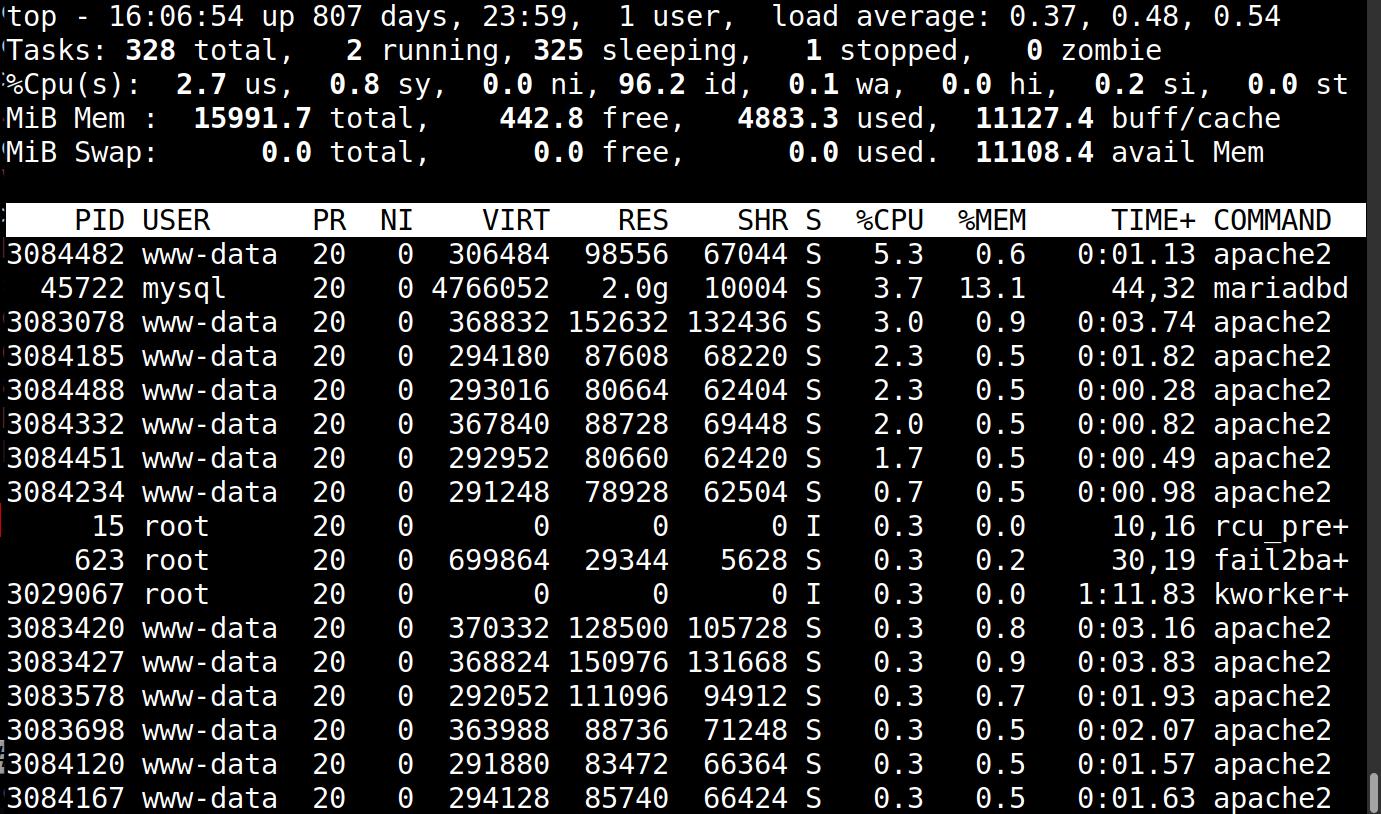
But there’s still no load? What’s going on!!!!
So I started wondering whether I’d disabled WP Super Cache (which serves out cached HTML without hitting the database much) while doing some experimentation the other week, but no. So I started thinking… “what if the problem isn’t WordPress per se, but just a lot of traffic — it just runs out of connections (due to KeepAlive and stuff)”…
So I googled, and Gemini told me what to fix (YES, AN LLM TO THE RESCUE, I couldn’t believe it either). It first told me to find out what kind of setup I have:
root@blogs:~# apache2ctl -V | grep MPM Server MPM: prefork
It’s mpm_prefork, which means that the conf is in /etc/apache2/mods-available/mpm_prefork.conf, so I upped everything there. So there’s now:
StartServers 5 MinSpareServers 5 MaxSpareServers 40 ServerLimit 1000 MaxRequestWorkers 1000 MaxConnectionsPerChild 0
That’s up from a standard of:
StartServers 5 MinSpareServers 5 MaxSpareServers 10 MaxRequestWorkers 150 MaxConnectionsPerChild 0
So I increased the (default) ServerLimit from 250 to 1000, and MaxRequestWorkers from 150 to 1000. I restarted Apache, and everything was suddenly hunky dory again.
The load, even with this configuration, is steadily less than 1, so it can probably be upped more.
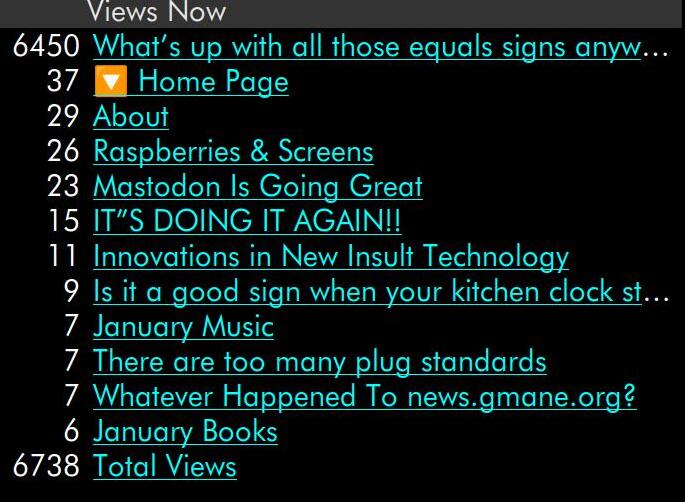
But how much traffic was causing this problem? Well, in general, there were just two page views per second (e.g., 6738 per hour in the snapshot above), but:

Each page view entails about 50 resource hits, so it’s about 100 hits per second.
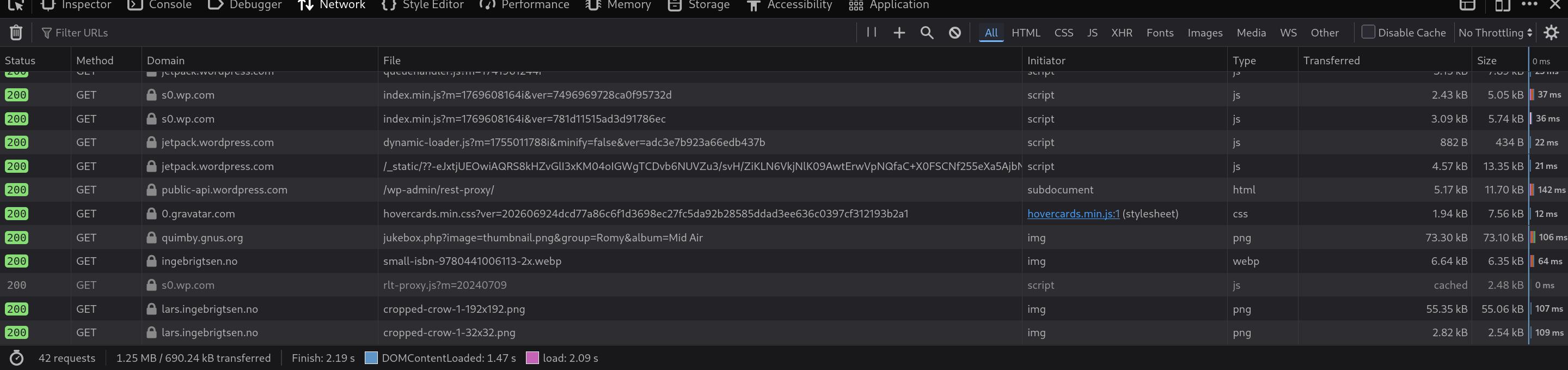
Which is nothing — you can see from the load that this Dropbox instance has no problem serving it, resource wise — but it’s just that the default connection parameters are really conservative.
Which may indeed make sense in other configurations. If each hit lands on an URL that requires a lot of processing, a limit of 1000 will soon land you with a server with a load of 1000, and you don’t want that. But a WordPress instance (with caching switched on) is 99% serving static resources only, which is *piffle*.
It’s deranged that we’re still doing stuff like this, thirty years after web servers got popular. There’s still no way to tell Apache “all of these resources are static, use how many connections you want — millions; I don’t care — to handle them. But these others (insert conf here) actually take CPU, so don’t handle more than 50 of them concurrently.”
So here we are… And now I can go back to rolling my eyes at those plebs that have server problems during hackernewsdotting. Hah!
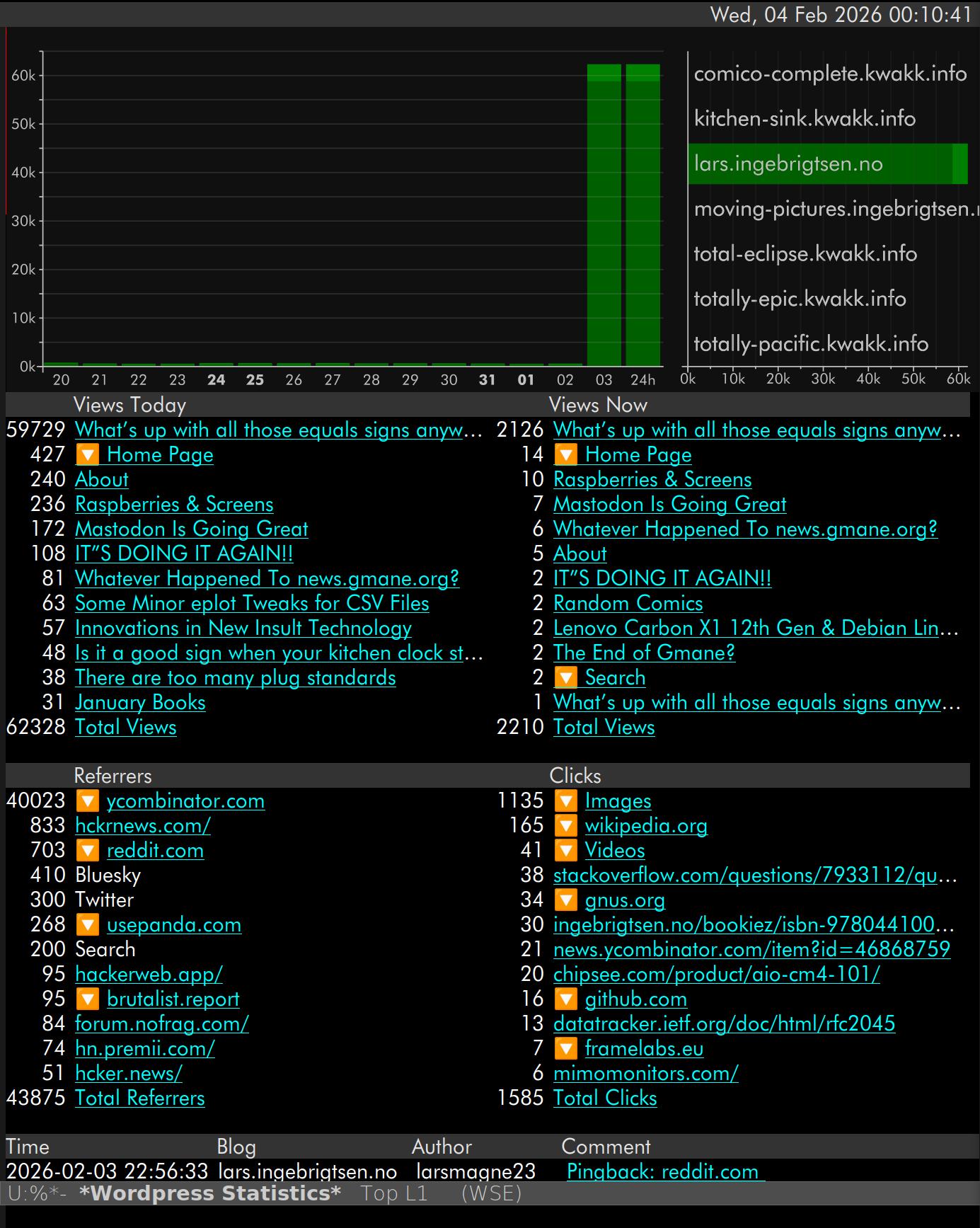
On this screenshot, it’s been about 12 hours now since the virality started viraling, and as you can see, it makes the daily chart useless — all the other days are just a couple pixels. I guess I could switch to a logarithmic chart, but I just don’t want to.
Seems we’re gonna land at, like, 65K page views in total for Feb. 4th — the previous record was 20K, so that explains that I had to tweak the Apache settings. Let’s see where we’re at now, about 24 after virality:

73K. Yeah, things have tapered off pretty quickly, but apparently Twitter has gotten into the business now:
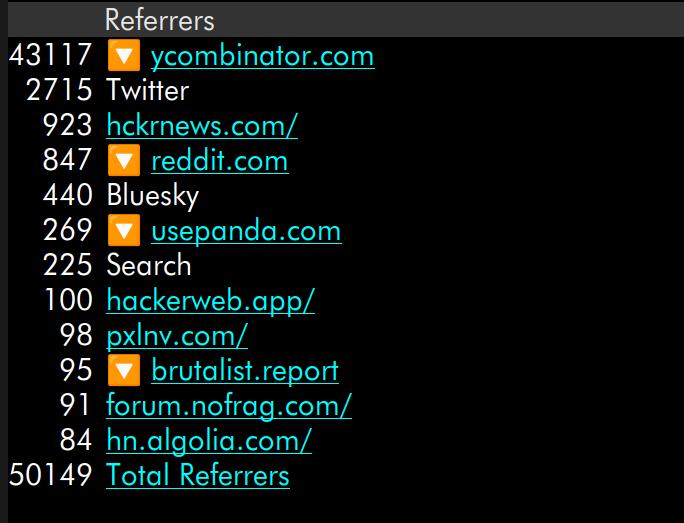
Oh, and Bluesky?
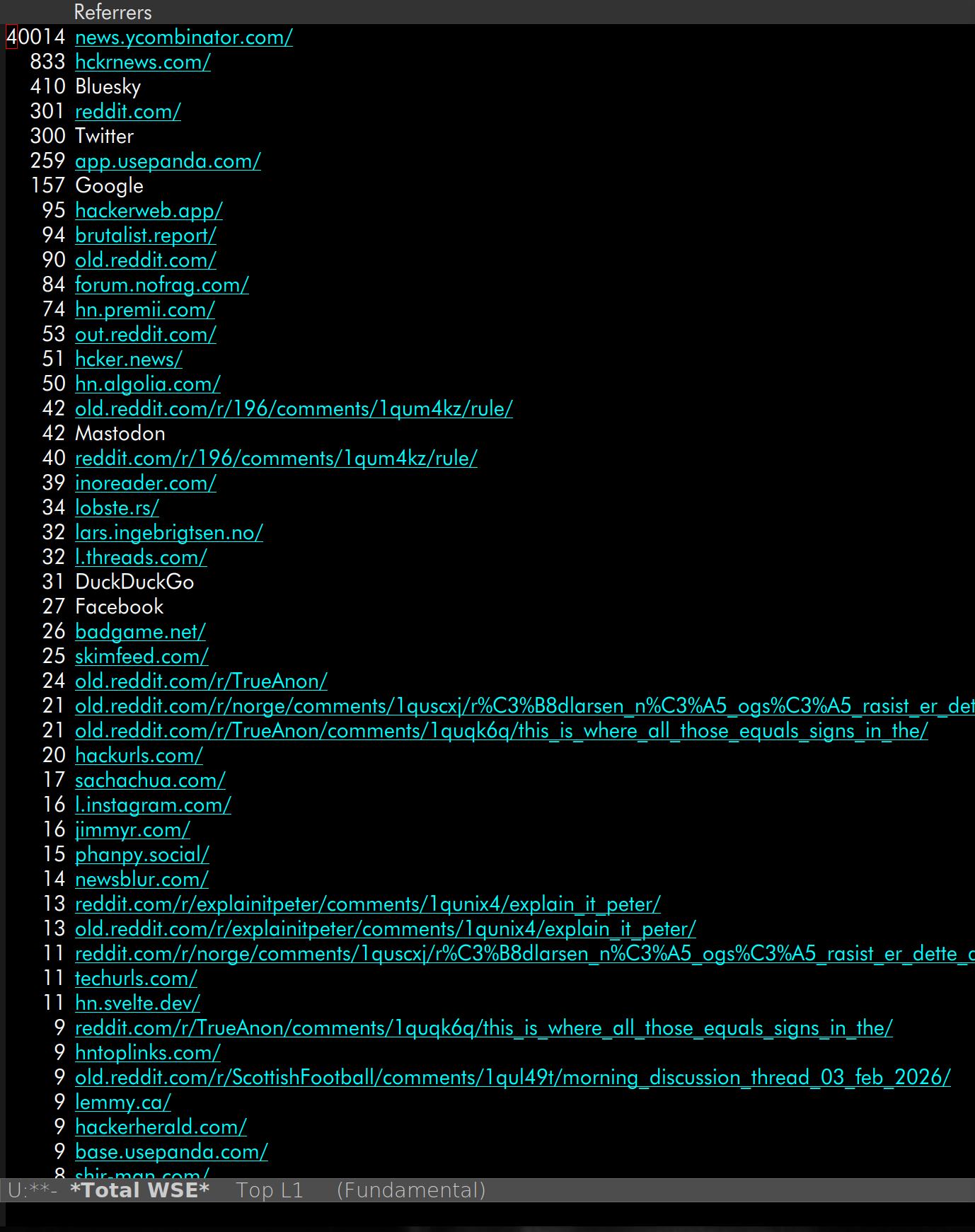
The referrers are fun — as usual whenever there’s a Hacker News post, there’s a large followup effect from Reddit etc. But the sheer variety… 250 different sites, and the list ends like:
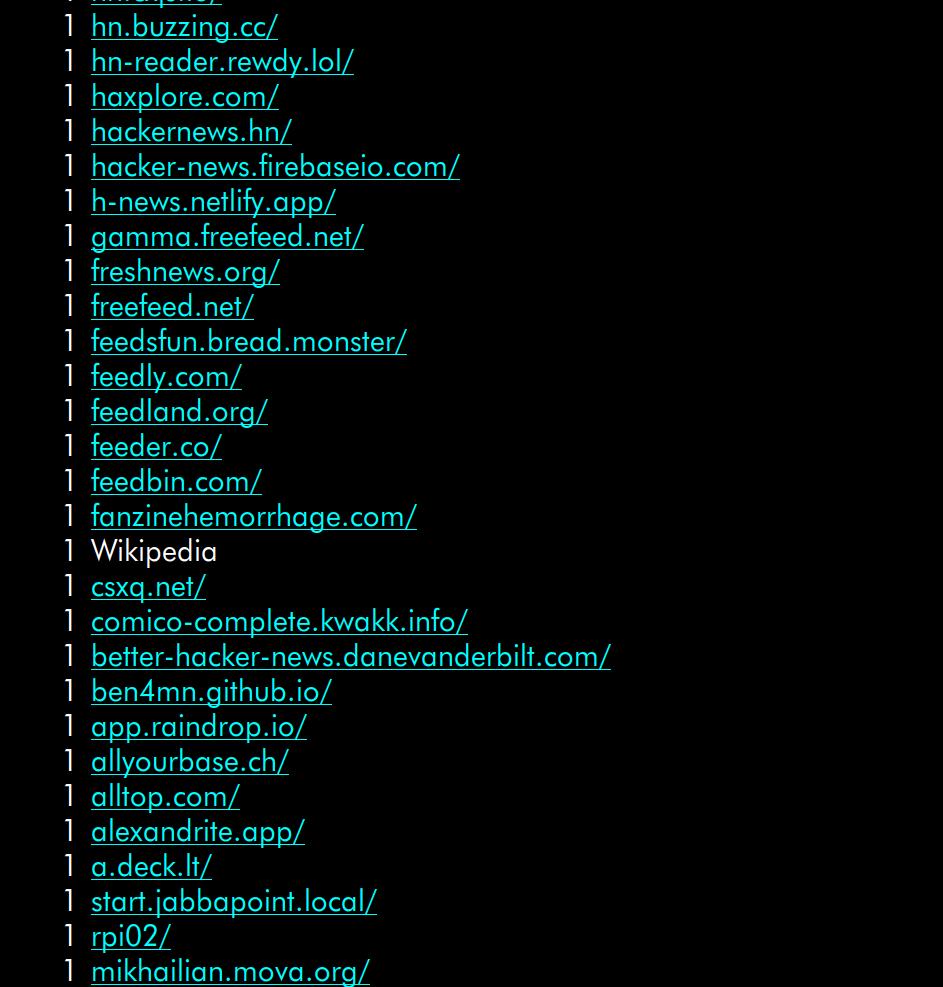
It’s a lot of stuff… so many web sites are downstream of Hacker News.
This ones‘s funny.
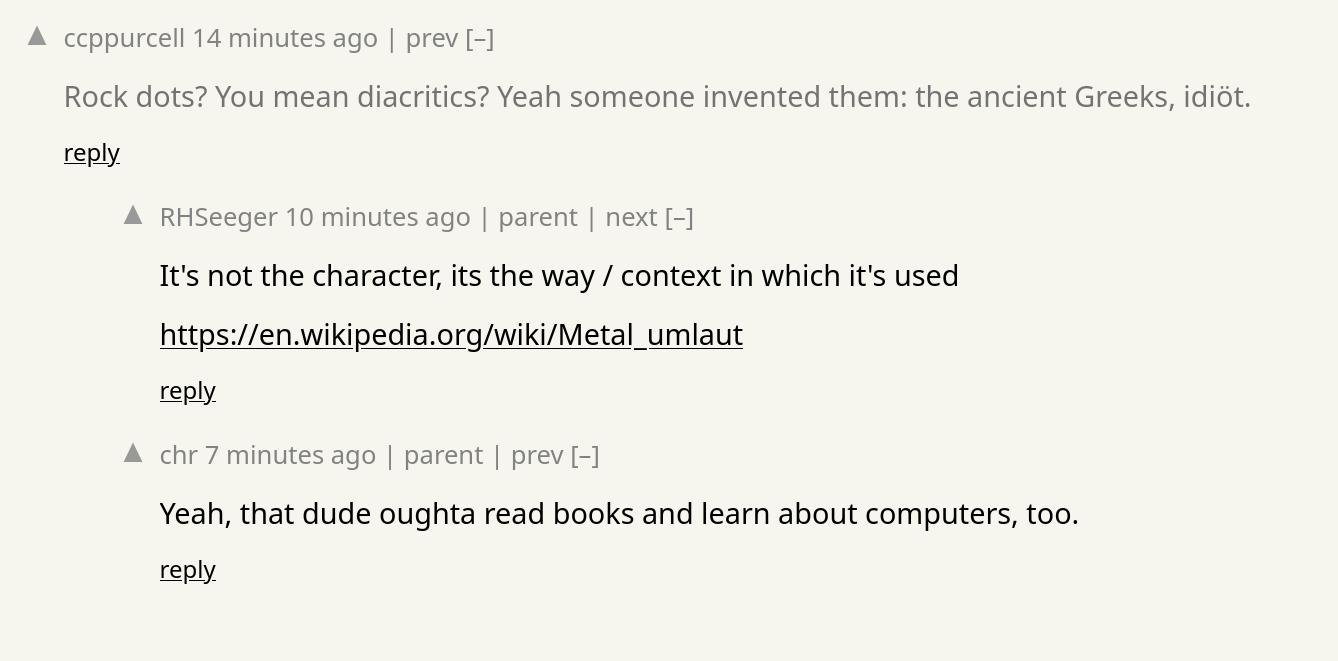
The comments on Hacker News were many and varied, but it’s kinda fun to see how the stupidest ones get downvoted pretty fast… As for comments here on this blog, I usually have WordPress auto-approve them (the Akismet anti-spam is so effective that it’s usually no problem), but some actual nazis found my blog, so I had to switch that off, and now I have to approve comments manually. Them’s the breaks.
So there you go.