

Does this look familiar to you?
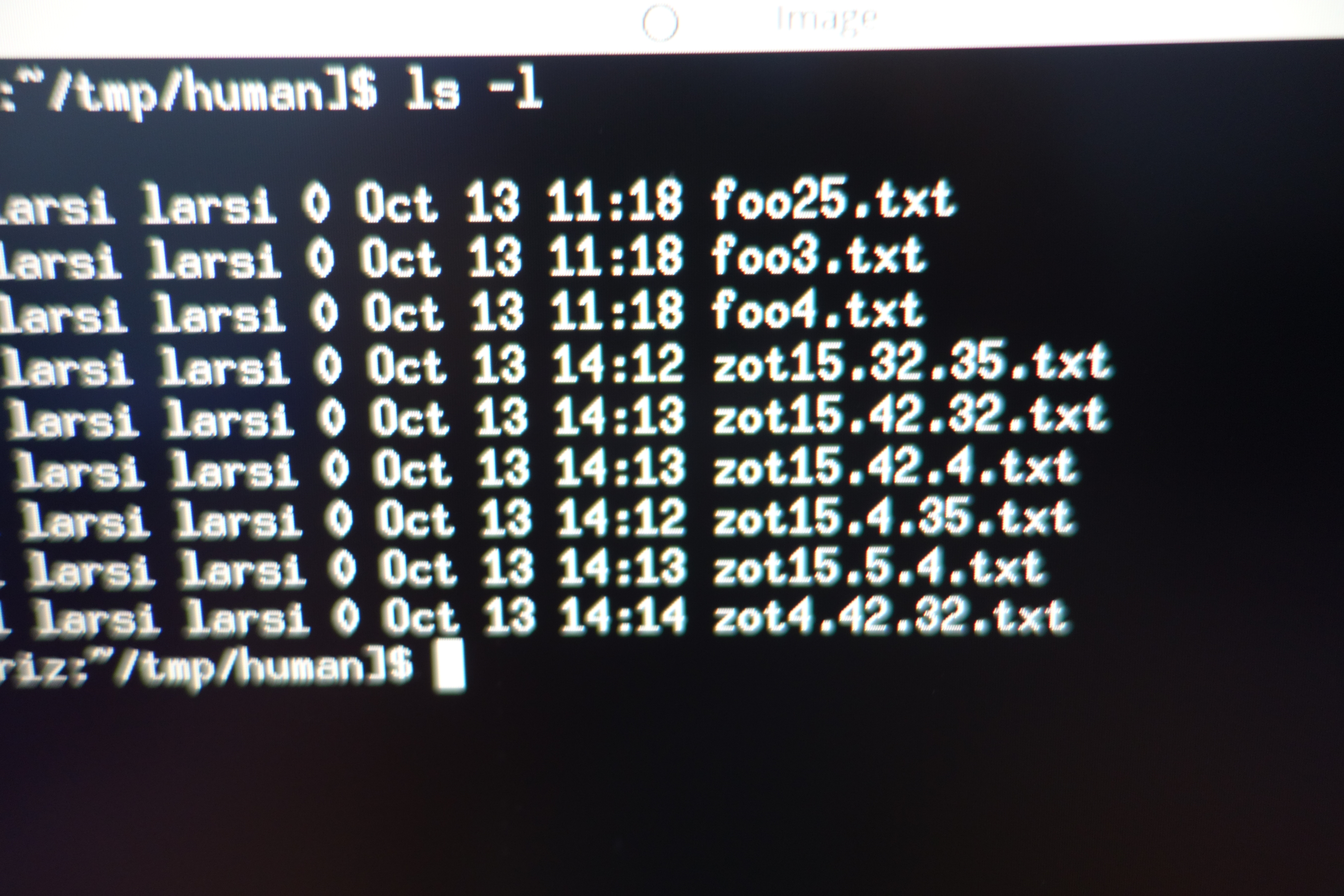
We’re humans. How would a human sort “foo25.txt” versus “foo3.txt”? We would think “hm, there’s some text, and there’s a number, and then there’s more text. Let’s sort the texty bits first, and then sort by number, and then sort the rest of the texty bits”.
That would make sense. But that’s not what’s been implemented, for the most part. Instead people are forced to create bug reports with names like “bug #000000001345” and keep track of the leading zeroes and hope that they’ll never need more. Because then everything will break down anyway.
It seems like a no-brainer to sort contiguous numerical parts as numbers. This solves most of our problems. But it’s interesting to consider whether this might be extended.
For instance, if you have “15.6%” and “15.16%”, you probably want the latter to be sorted before the former. If you split them into two numerical chunks, you’d instead get the former ahead of the latter.
It’s common to write numbers with other characters in the middle to break up the long stream of digits. In the US, you write “10,000,004” for ten million and four. It would be nice if that sorted after “20”. In some other countries you’d write “10.000.004” for the same number. In India you’d write “1,00,00,004”.
If you have a version number like “Gnus 5.15.5”, then that’s a later version than “Gnus 5.6” and “Gnus 5.6.4”.
So we quickly run into consistency problems if we try to be too clever. On the other hand, we’re can probably get the computer to sort better than most humans would.
But surely I can’t be the first person to think of this major and pressing issue. Surely somebody has doing something awesome here.
Let’s take a look at Explorer in Windows:
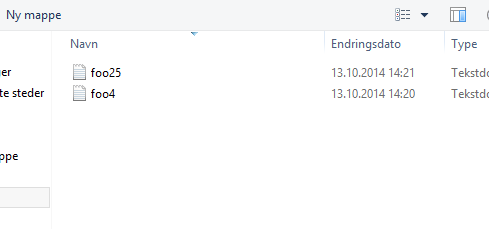
Nope. “foo25.txt” sorts before “foo4.txt”. Bad Bill. (Edit: I’m being informed that I must have clicked on something, because Windows Explorer does allegedly sort correctly.)
What about OS X:
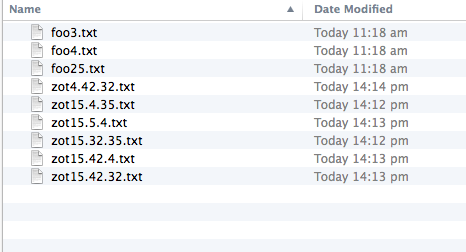
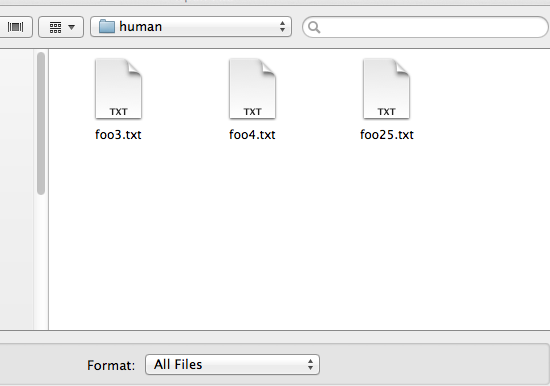
Ok, so I wasn’t the first one to consider this. In Unix tool land, we have “sort -g” that will interpret contiguous digits, including decimal points, as numbers instead of strings. And they’ve recentlishly added “-human-numeric-sort” that, if I understand correctly, does exactly the same as “sort -g”, but also interprets SI units lik “G” and “M”, so that you can say “du -h | sort -h” and get the result you desire instead of the useless default sorting method.
Anyway, we must adapt this to Emacs. Dired should definitely sort more humanely, but how ambitious should we be? Just go for contiguous digits, or try to interpret “number clusters” more freely?
I’ve made a proof of concept on Github (written in the most inefficient way possible) instead of just putting this into Emacs immediately. It just does the “contiguous digit” thing at present, so that “foo25.txt” sorts after “foo4.txt”.
What do you think? How far should Dired (and the like) go in this direction?