

In connection with my grand Fantagraphics re-reading project, 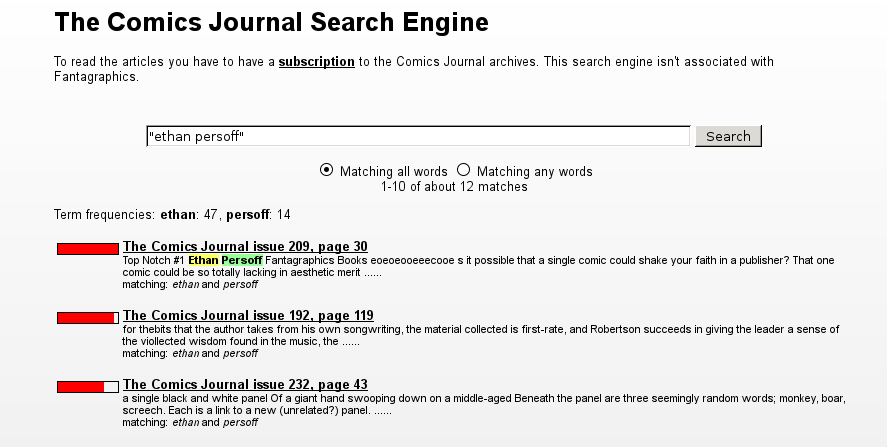
That turned out to be easier said than done, because the TCJ archive consists of one scanned JPEG per Comics Journal page, and there’s no usable index or search engine there. So after pondering a bit, I decided to just run the whole thing through OCR and create a search index myself.
You can find the source code on github.
Now, to actually read the archive pages, you have to have a subscription. There’s nothing of interest on the search engine if you haven’t got one. So this will probably be useful to approximately seven people worldwide, ever.
And I don’t really have the right to do any of this, so: If anybody at Fantagraphics objects to the existence of this search engine, please let me know, and I’ll remove it from public view, and just continue to use it myself.
But here’s the link to the search engine.
Technical notes: I signed up to ocr.space to do the OCR. I paid for a one month subscription, and the service was pretty snappy and yielded good results on most issues. But the results on the first years were pretty horrible: It doesn’t understand the font the Comics Journal used in the 70s, so you’ll get no or very few results from the earliest years. The TCJ archive doesn’t use a quite consistent URL scheme, either, so there’s a handful of issues with wrong links. But it mostly works.
I examined various search engines before going with Xapian Omega. It’s fast and snappy and seems to give satisfartory results. I used cdb to create a mapping between the search results and the Comics Journal archive URLs.

If you have a subscription to the archive, it’s now easy to find that article where R. Fiore listed Hugo as one of the years best comics, and didn’t list Love and Rockets.
Hours and hours of fun.