

I’ve written previously about the problem of screenshotting web pages (which I think is a bit important for web preservation) and how my solution was to use the Easylist/Ublock block lists to remove annoyances like cookie banners (that often just obscure the entire page).
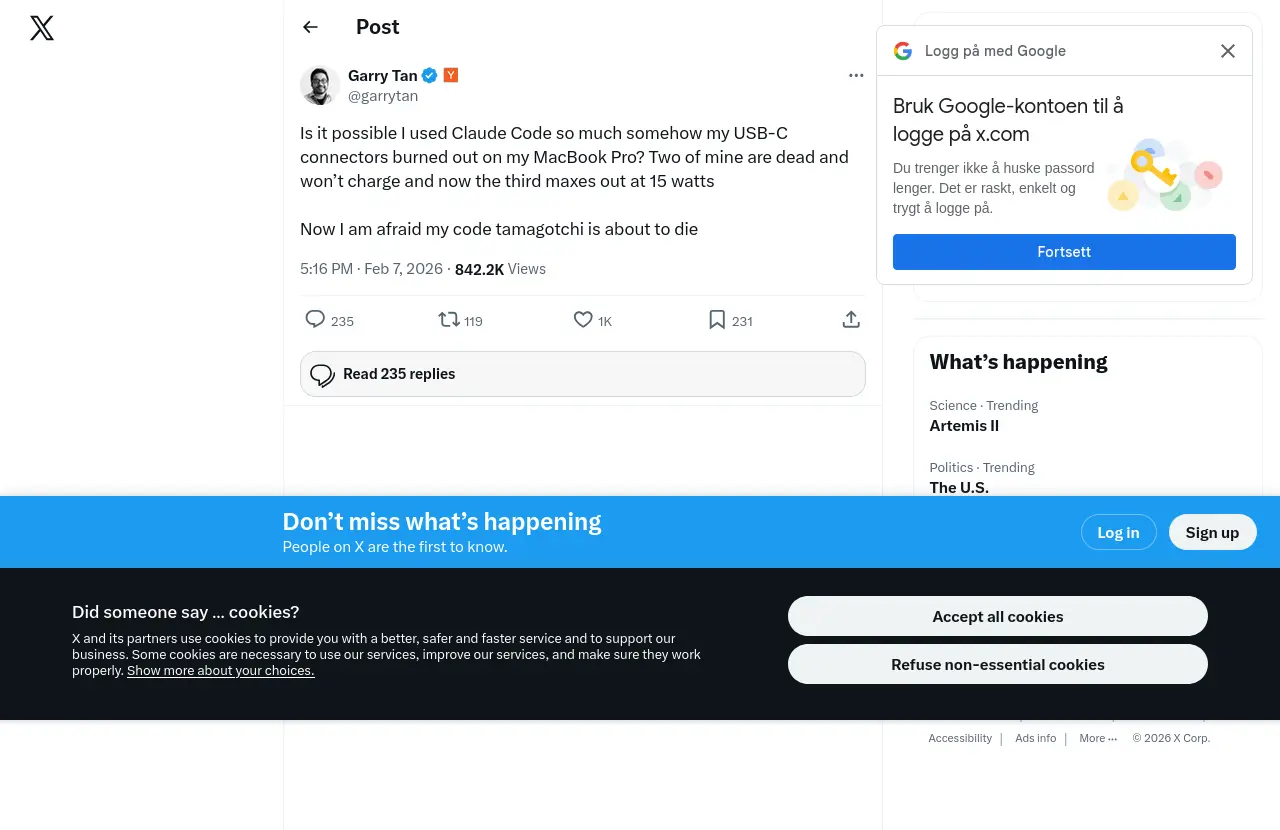
And it seemed to work pretty well… except on sites like Twitter, where the banners stubbornly remain. I assumed that the HTML was just so obfuscated there that things didn’t work at all, but after thinking about it some more, that just seemed unlikely to me: These lists are updated pretty often, and these are big sites, so you’d think the list people would be handling it.
Less than ideal, eh?
So I started debugging, and it turns out that there are two kinds of selectors — normal DOM selectors, and extended selectors, and my code was just ignoring all those extended rules.
Now, writing code to emulate Ublock Origin here sounded like a lot of work, so I just asked ChatGPT to do it, and after prodding it to really do it a couple times, it apparently did. It spat out 830 lines of code, and after hooking that up to the screenshot thing:
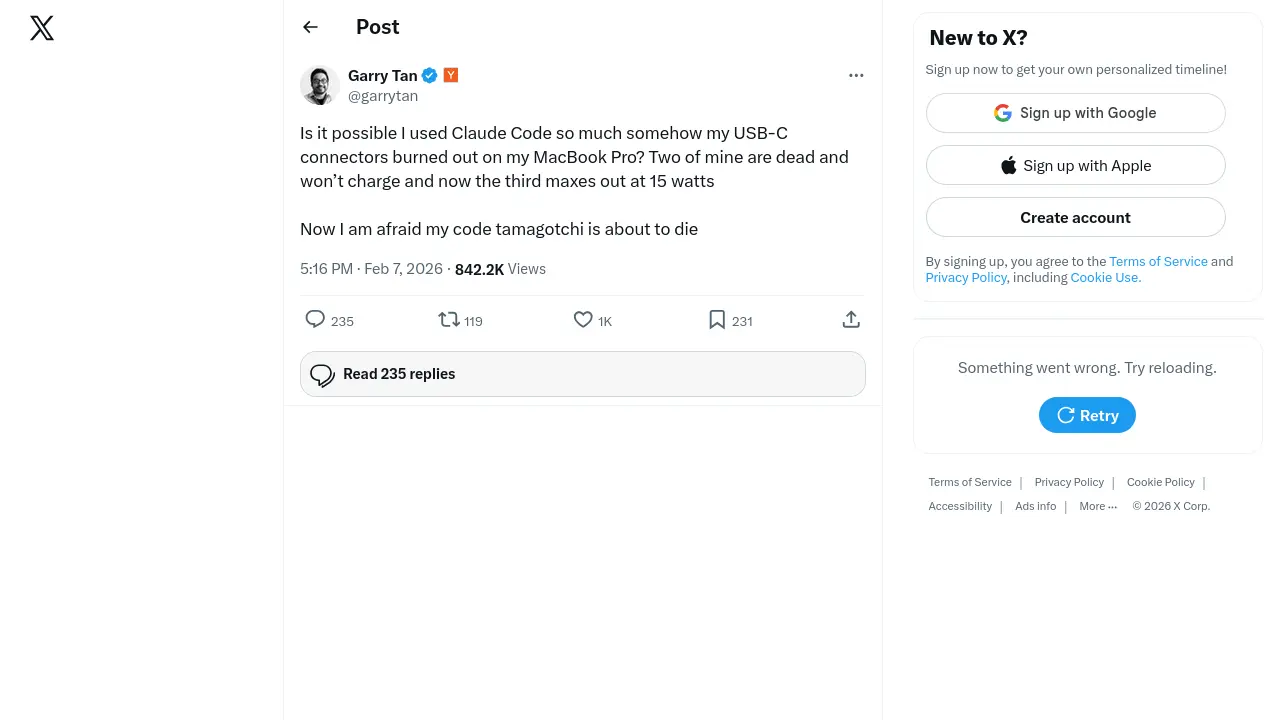
It works! I’m sure it plagiarised a bunch of code to do this, but…
I’m kinda starting to understand how people end up in LLM psychosis — you can just do things that would take you so long to do manually that you wouldn’t bother to even attempt doing them…
Rah rah LLMs?