

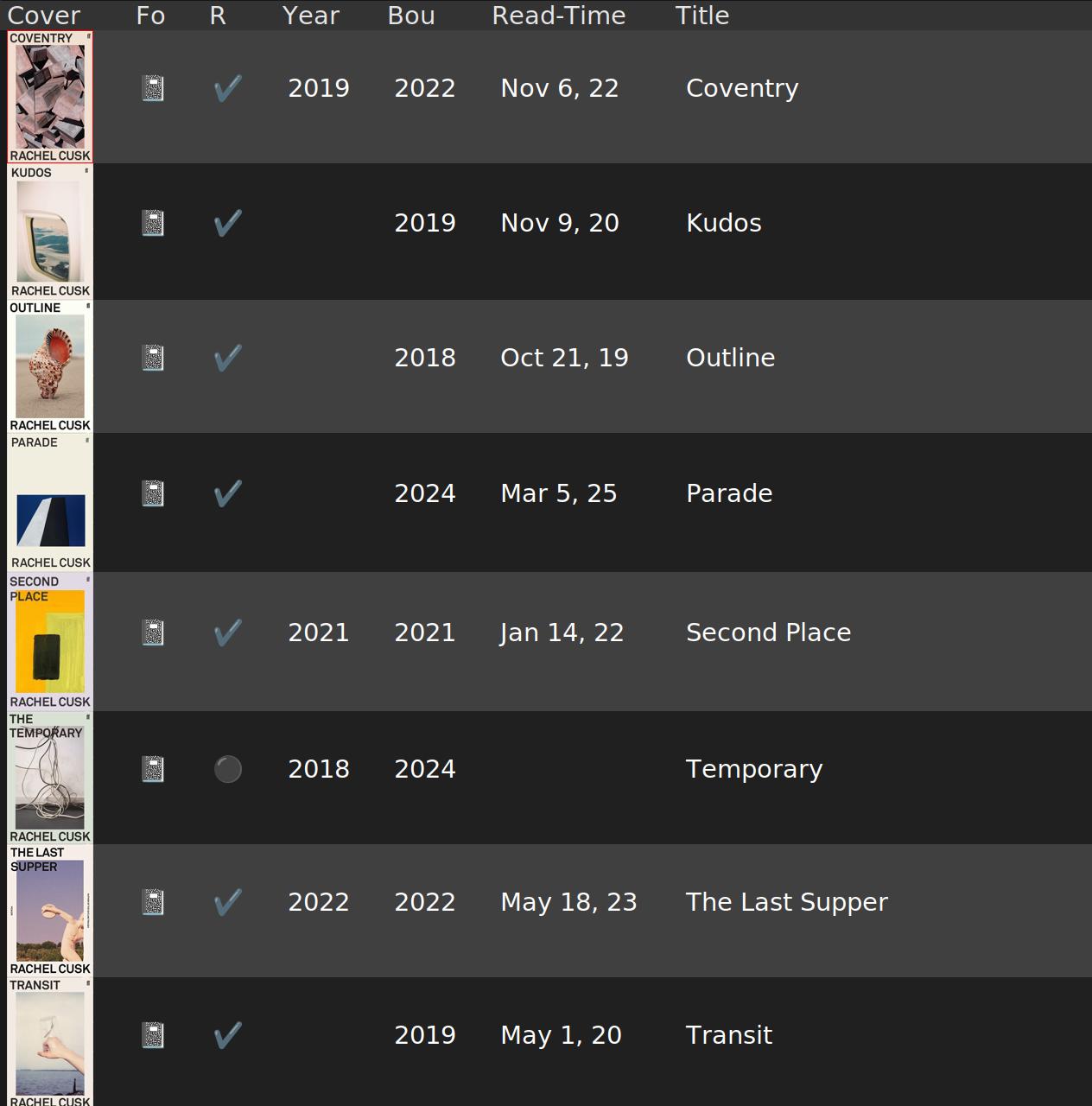
In 2013, I got tired of rooting through the book cases every time I bought a new book (to see whether I already had it, because who can remember those things).

So I bought an ISBN bar scanner, and whipped up some basic code in Emacs to keep track of what I’d bought. I’ve used it for over a decade now, and it works fine, but it’s super duper basic:
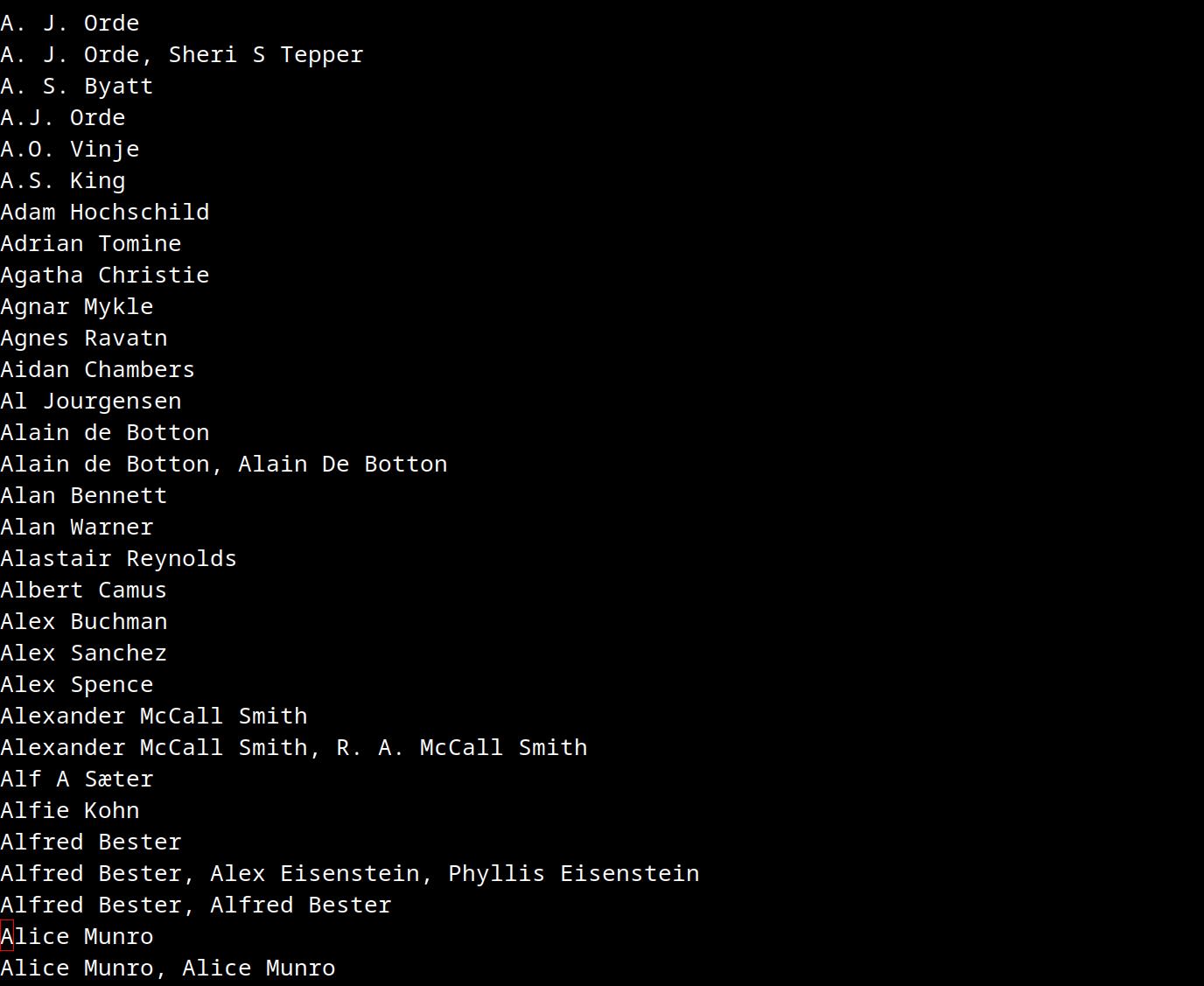
It’s basically just a buffer that lists all the authors, and then if you click them, you get:
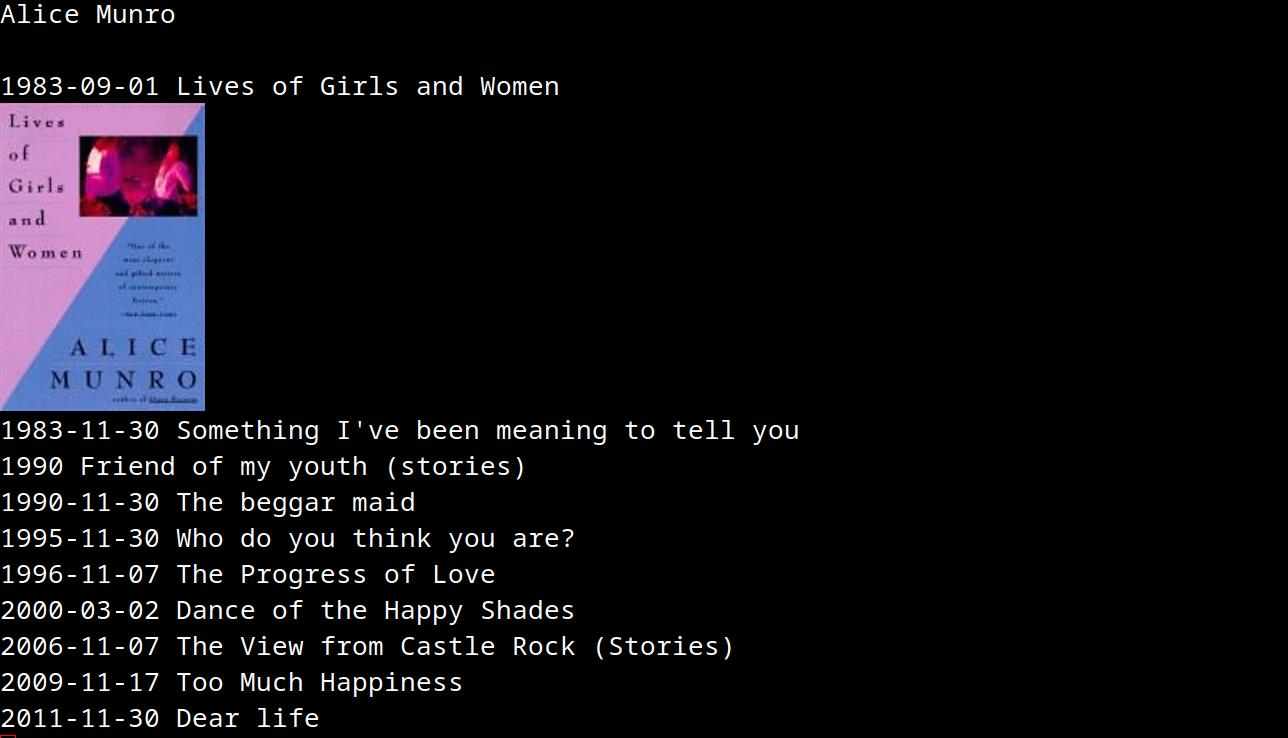
A list of all the books from that author, as well as the registered publication date.
So that’s fine, but:

The data quality from the various ISBN lookup providers is pretty bad. I mean, it’s not only the inconsistency, but it’s also sometimes altogether wrong, because ISBN reuse is a thing, unfortunately.
In addition, I’ve been buying ebooks too, and these are totally outside this system. Whenever I buy a papery physical book, I blitz it with the bar code scanner, and it’s registered — it takes me literally two seconds or less. With ebooks, I’ve got no system at all, and I’m buying via three different online stores, so my book shopping headache has reestablished itself.
So I hear what you’re saying: Just bite the bullet and use Librarything for everything. And I say: No! So there! stomps foot
Voila!

I spent one day tinkering with this thing, and now I can edit the data to satisfy my CDO (it’s like OCD, only the letters are in the proper alphabetical order), and I can add ebooks (manually-ish, sigh). When the data is easily available like this, the obvious errors (like with the author name above) can be fixed very quickly.
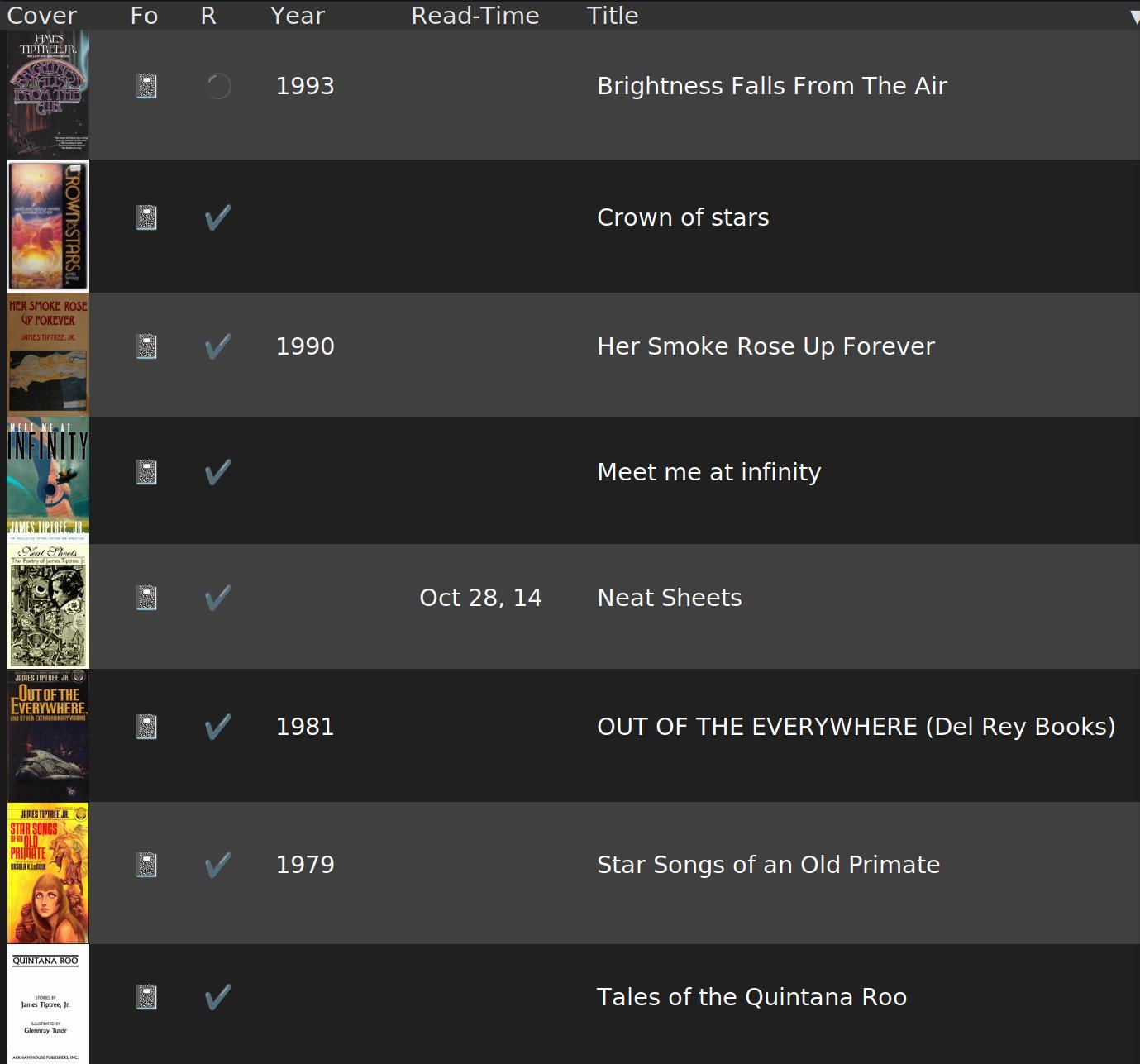
I added more support to the isbn.el library to do Goodreads queries, too. Goodreads doesn’t have an API any more, so I have to do some web scraping, which sucks, but this increased the number of book covers by 180%, since the services that do have an API aren’t as comprehensive. So whatchagonnado.

Covers are nice.

I also added a new command to just list all the books in one big buffer:
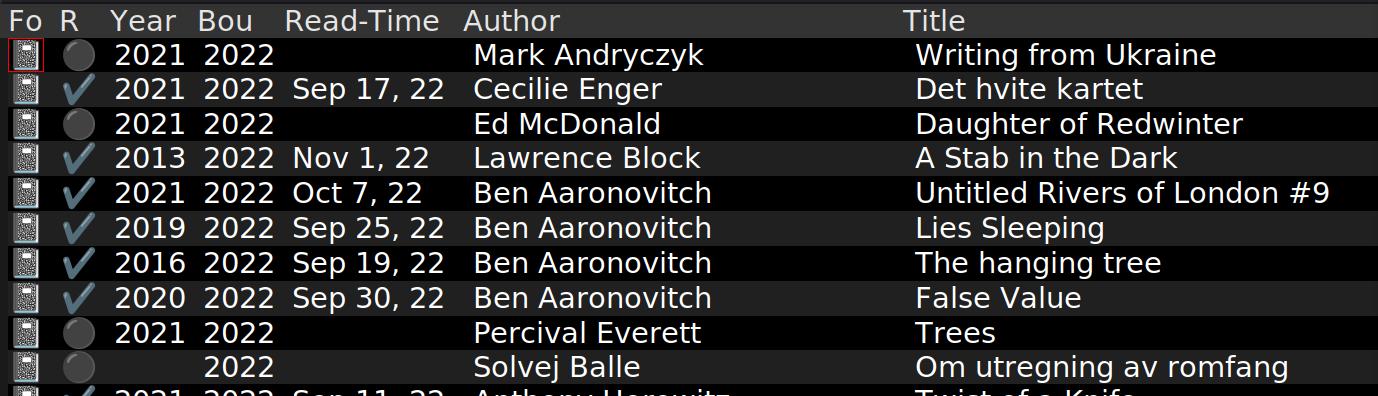
Because I realised that having a buffer with authors, and then books by specific authors is all well and fine, but it’s really just much faster to C-s for a book name than to first find the author, and then find the book. I mean, I’ve not got a million books; it’s just er:

That many.
Hey, now I can get data out of this thing by just clicking on the columns… Let’s see… I’ve got 432 unread books! Sure! I’ll get to them all one day.
(Actually, looking over that list, it looks like I’ve forgotten to mark a large number of books as read… uhm… I’m guesstimating about 100? I should revise the data one of these days.)
Anyway, the code is on Microsoft Github. I’m not sure anybody would find this usable as is, but perhaps there’s some useful bits. At least the isbn.el library in there is somewhat helpful.