

I’ve always been frustrated by the IMDB web pages. Usually when I’m looking at a director’s oeuvre, I’m not interested in all the shorts, videos and games the director has created, but just want a list of the movies.
When I’m looking at a specific movie, it’s often because I want to know who the character on the screen I’m watching is being played by, but the images are so tiny and low res that it’s impossible to guess who’s who.
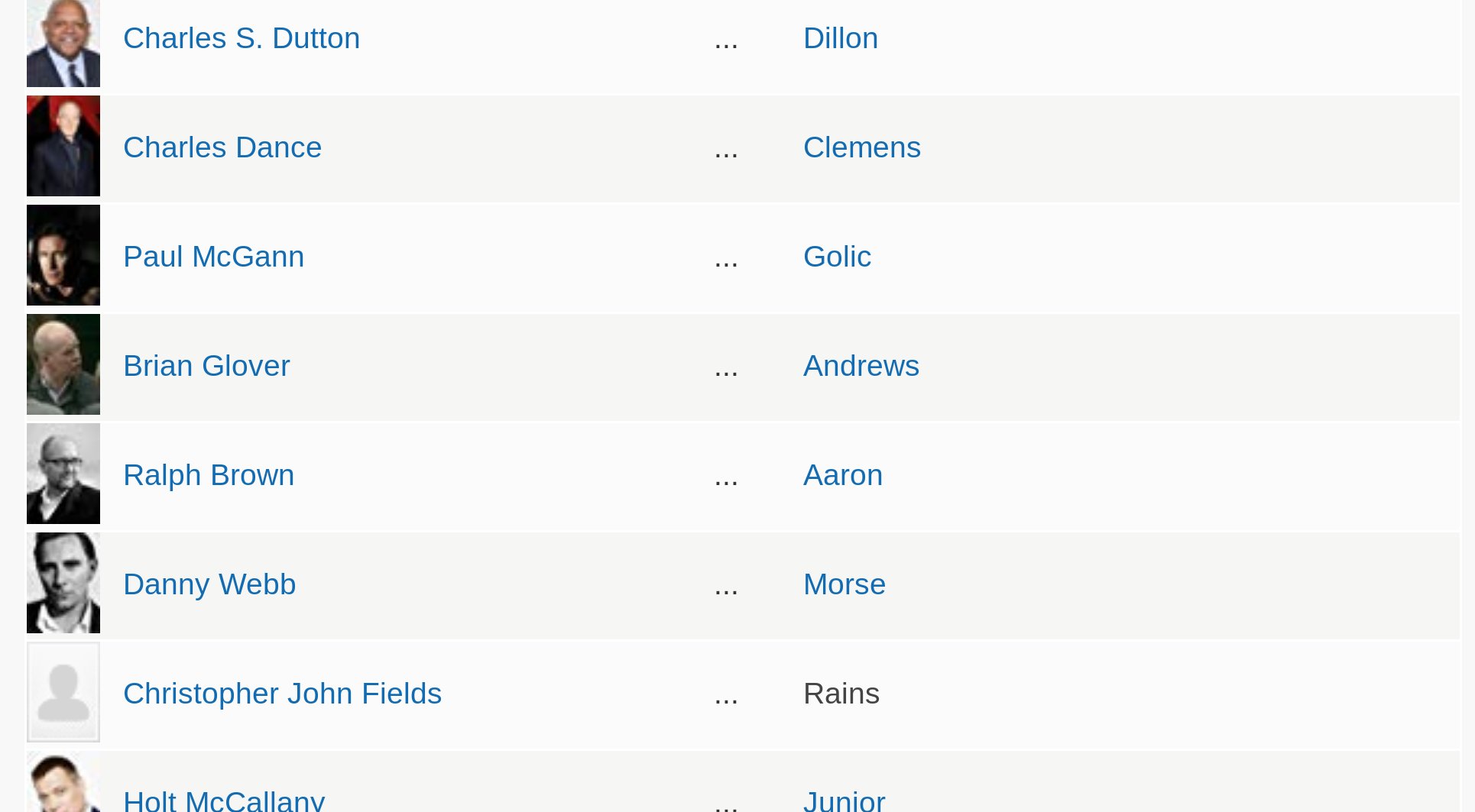
And once I found myself wondering, “what’s the name of that actor that played in that film with her and her”, and I know who the latter two are, but not what film, so it would be nice to be able to do a cross reference kind of thing… right? RIGHT!?
OK, the last thing happened only once, but it was still something that I thought might perhaps have been vaguely useful. But, of course, I didn’t do anything about all this because well you know.
I did download the IMDB data set and do various things with it (but mostly based on grepping and ad-hoc searches), but that came to a complete stop when IMDB revamped their data exports. Instead of semi-human semi-readable files, it’s now basically a database dump. No longer can you just grep for “Isaach De Bankolé”, because in the new files, you first have to find his ID, and then you can grep for that, but that just gives you movie IDs, and…
Long story short, I made an Emacs mode for looking at the new-format data.
It’s based on this sqlite3 module for Emacs. My first attempt was based on just storing all the data in hash tables in Emacs, because I’ve got lots of RAM. I thought that since I routinely open multi-gigabyte buffers in Emacs, and that’s no problem, and at work, I routinely have multi-tens-of-gigabyte processes in Common Lisp servers, that should be no problem in Emacs either.
I had forgotten that Emacs’ garbage collector is, er, kinda primitive. It’s an old-style stop-and-copy collector. This is fine for huge buffers, because that’s basically just a handful of objects, no matter how large the buffer is. When you create a 200M element hash table, all those elements need to be mark-and-sweeped individually, and as I found halfway through implementing it, that makes Emacs pause for like ten minutes at a time.
So scratch that. I went for sqlite3 and I store the data on disk. But interacting directly with the sqlite3 database data is a drag, so I wrote a kind of ORM… well, it’s more of a PRM. Plist-Relational Mapping. Because strong typing is for dweebs.
I mean, professionals.
Anyway, the raw dataset from IMDB is about 3GB. The sqlite3 database is about 7GB, and takes an hour or two to create on my machine. (Before I found out that sqlite3 autocommits by default, I had like two transactions per second. By slapping a transaction around the import, I get a few thousands of inserts per second.)
The module has some bugs, but I’ve sent a pull request, so hopefully it gets fixed. Or pull down my fork instead, which is here, and you’ll need it to do regexp searches.
If you want to play with this, you need a newish Emacs built with module support, the sqlite3 module, and imdb-mode.el.
And then just eval (imdb-download-and-create) and wait for a few hours.
The PRM works pretty much as you’d expect.
(imdb-select 'movie :mid "tt0090798") => ((:_type movie :mid "tt0090798" :type "movie" :primary-title "Caravaggio" :original-title "Caravaggio" :adultp "N" :start-year 1986 :end-year nil :length 93))
See?
(pp (imdb-select 'crew :mid "tt0090798") (current-buffer)) ((:_type crew :mid "tt0090798" :pid "nm0147599" :category "writer") (:_type crew :mid "tt0090798" :pid "nm0413897" :category "writer") (:_type crew :mid "tt0090798" :pid "nm0418746" :category "director") (:_type crew :mid "tt0090798" :pid "nm0418746" :category "writer"))
Easy!
(imdb-select 'person :pid "nm0147599") => ((:_type person :pid "nm0147599" :primary-name "Suso Cecchi D'Amico" :birth-year 1914 :death-year 2010))
Anyway, that’s the low-level interface. Here’s what the user interface looks like:
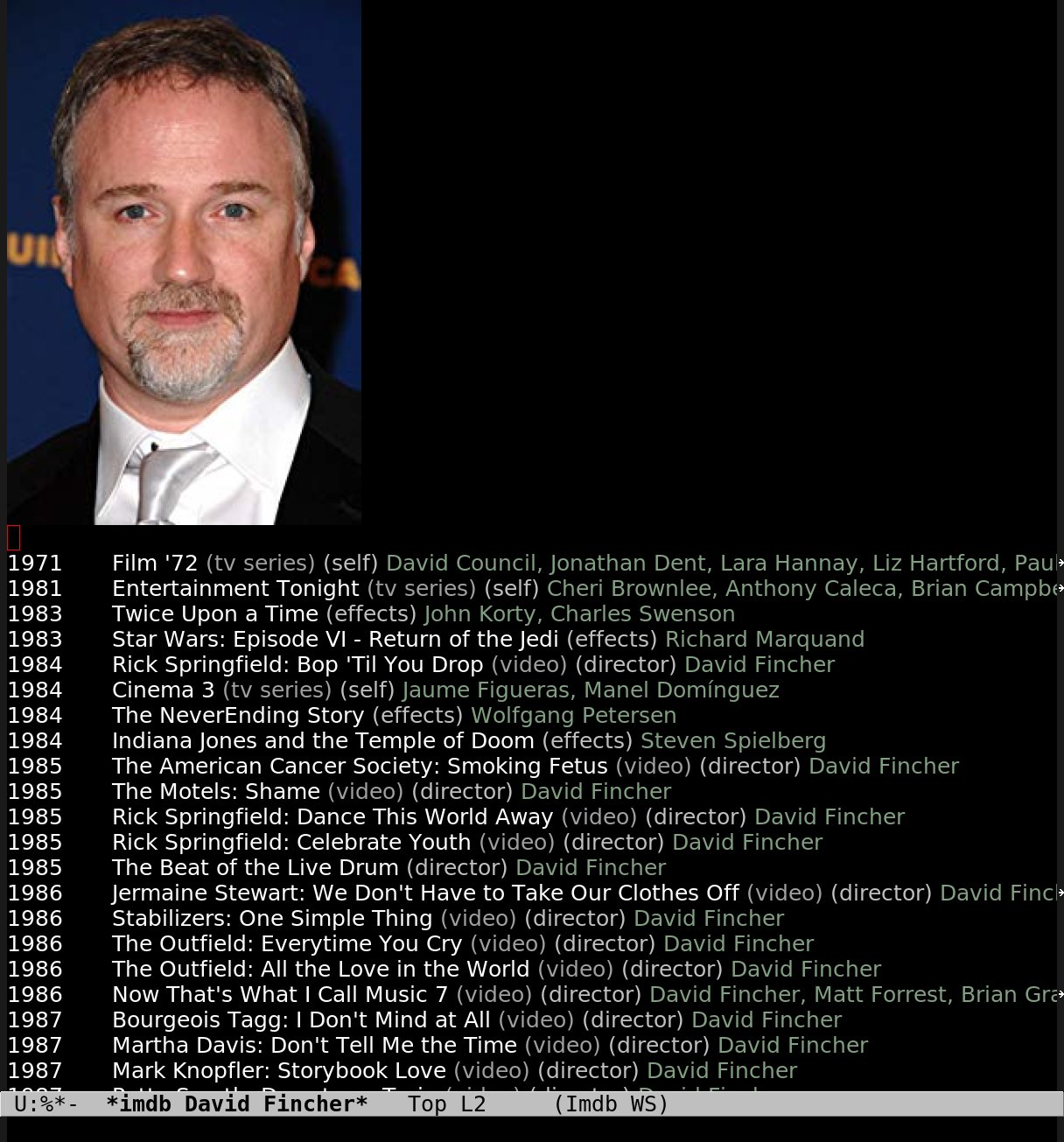
And then “x” and the noise is gone!!!

Only the real movies! *gasp* It cannot be!
(I didn’t choose Fincher here because I like his films, but because he’s done so much junk that’s it’s impossible to use his IMDB page.)
But… when looking at some actors I knew pretty well, I soon noticed that not all the films that the actor appeared in were listed. Here’s Tilda Swinton most recent few years:

What’s going on?! No Doctor Strange? Could there be a bug in my code? That seems impossible? I mean, it’s my code!
But nope, the problem is with the IMDB dataset. The file that lists what films actors appear in, “title.principals.tsv”, isn’t a complete list of participants, but instead, as the name really sorta kinda implies, a list of the most important people in that film. That means that it lists directors, writers, the cinematographer, (some) producers and then a few actors. But never more than ten people per film.
This is really weird, because directors and writers are already in the “title.crew.tsv” file.
This made me sad until I realised that I could just resort to web scraping.

So now I use the data set as a base and then insert the missing things afterwards.
Doctor Strange!
And when I’ve resorted to web scraping for that, I can just scrape for actor images, too:
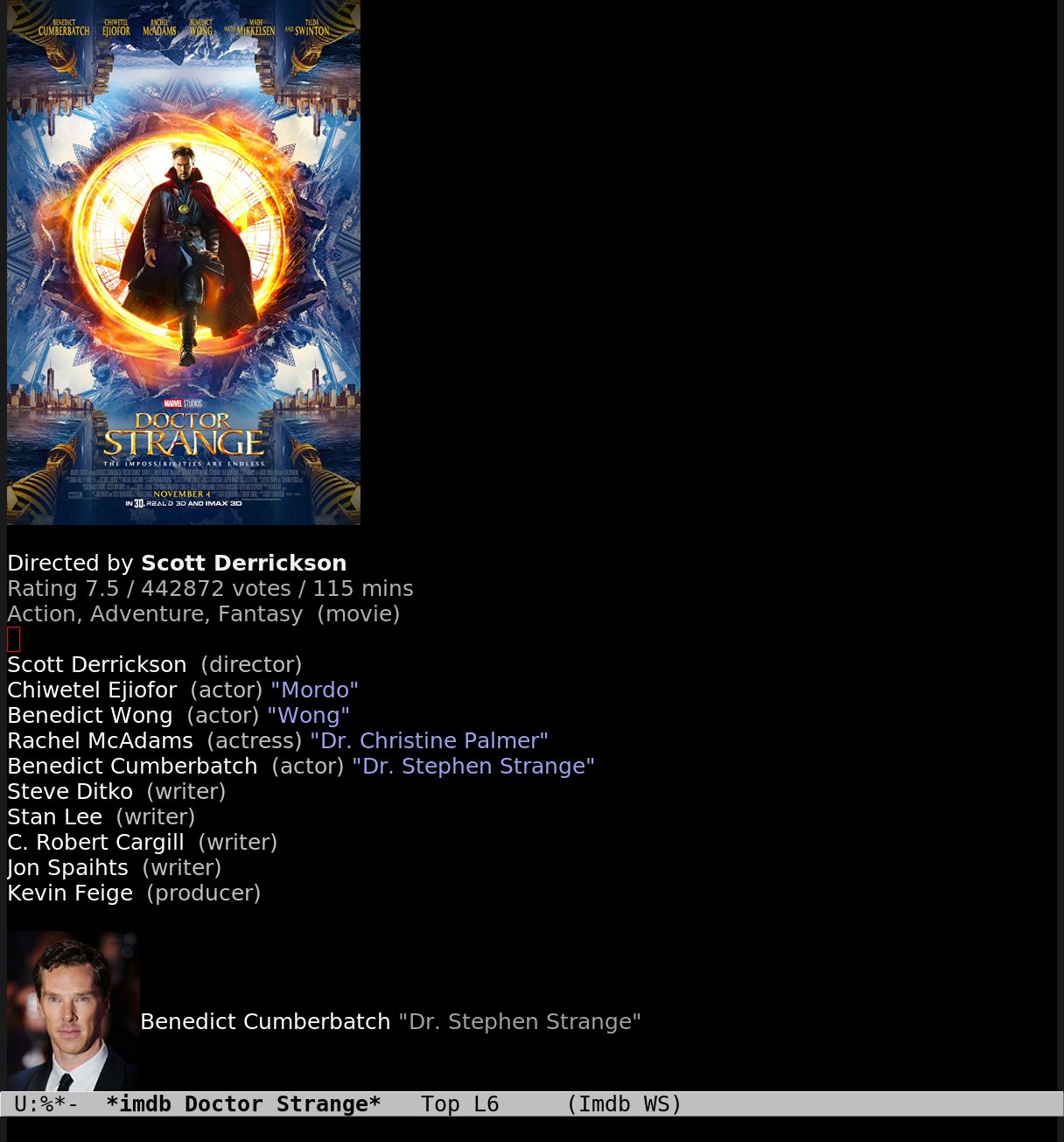
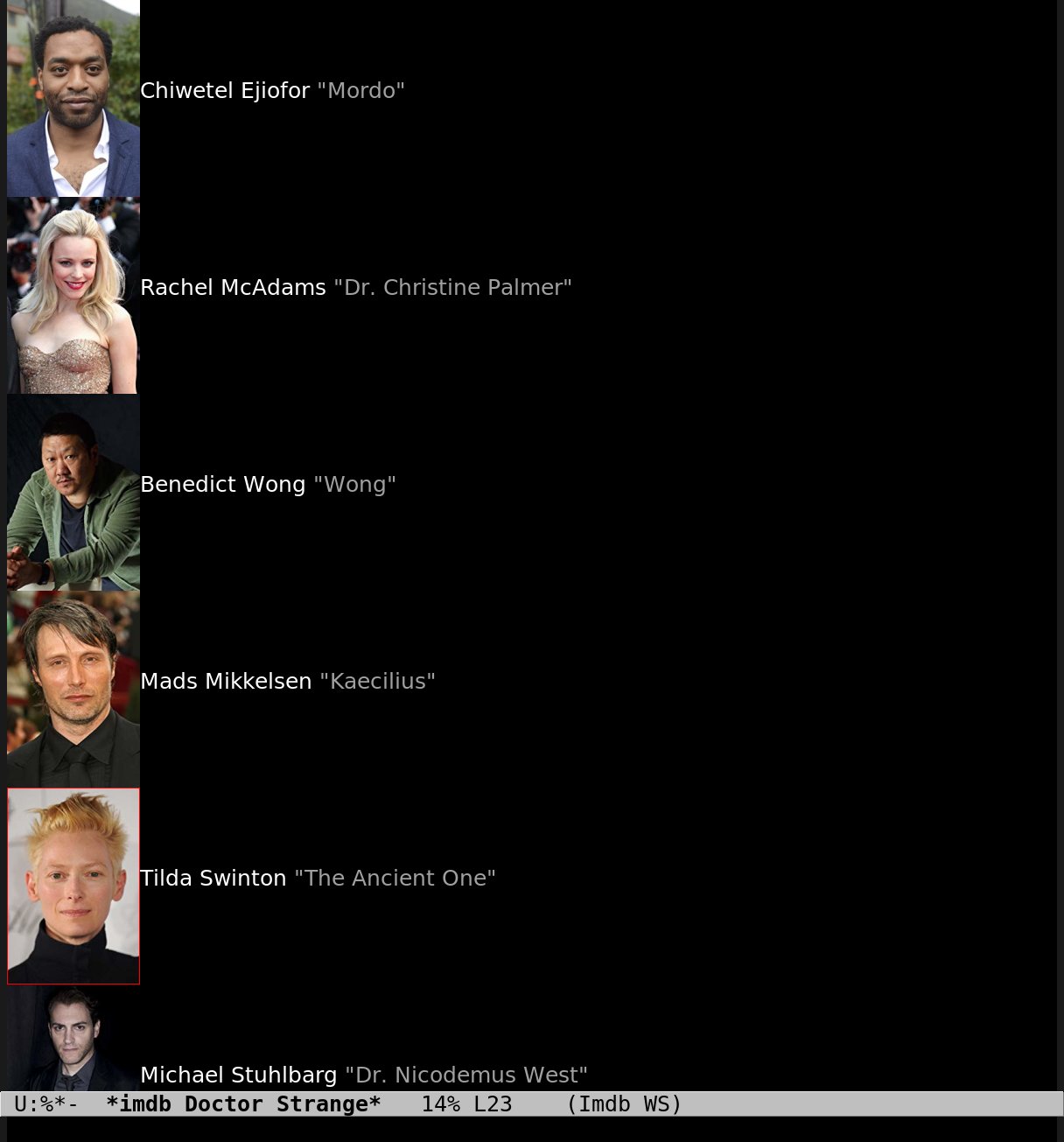
*sigh*
In short, IMDB doesn’t have a usable API, and IMDB no longer export enough data to do anything useful with that data. So I guess this Emacs mode will work until they tweak their HTML.
While implementing the scraping, IMDB suddenly went missing and I just got:
I then found out that I had er slightly miswritten the end of the recursion, so I was hitting imdb.com with dozens of invalid hits per second in several concurrent threads. I AM SORRY IMDB.
They unblocked me after an hour.
Here’s what it looks like in action:
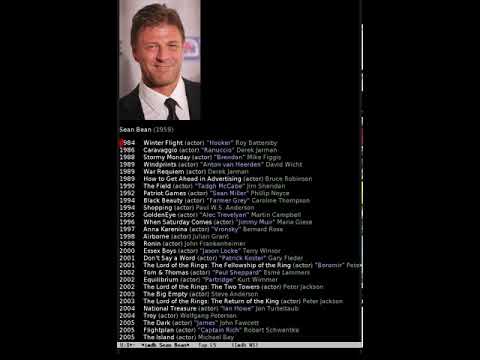
(Click on the embiggen symbol to embiggen so that you can see what’s going on.)
I’m like, selecting a few things and then toggling what bits to see (acting/directing/all/shorts).
Exciting!
And now it’s feature complete, too, so I’ve definitely saved a lot of time by writing this.
Er… Oh, yeah. I was going to implement intersections (i.e., list movies that have several specific people involved. So let’s see which films Tilda Swinton did with Luca Guadagnino:

Easy peasy. Or the more complete, unfiltered version:

Heh. I think “Dias de cine” and stuff are just Italian long-running movie news shows that both of them have appeared on? Or in the same episode? Hm… probably the latter, because each TV episode has its own unique ID.