


I know that LLM usage is controversial, especially in comics circles. And of course it is — generative AI is a plagiarism machine, and people trying to use it for art are ridiculous.
But on the other hand, LLMs are somewhat useful for trying to zoom in on non-clear data. Of course, most of what you get out is nonsense, still, but for data that has never been systematised, you can use it to find where you’re supposed to read, at least.
So here I am with kwakk.info, which has about a million pages from fanzines and magazines about comics. And the search index is indeed very useful, and what I use all the time to see what people thought about various comics. But it’s pretty much useless for tasks like “I want a list of comics-related fanzines from the 60s, ranked by popularity”.
I wondered whether I could point an LLM at my data set and make it cough up interesting things like that, and so…
… I asked an LLM what to do.
GOOD!? Anyway, I spent an hour or so being the go-between, and:
![]()

Now it’s gonna be working for 17 hours, ingesting all those pages.
I can really understand now why LLM Agents have gotten so popular — it feels pretty stupid, sitting here cut and pasting between the LLM and the console. “Why can’t it just do that itself!?” And then you end up with your root file system gone and a very contrite LLM.
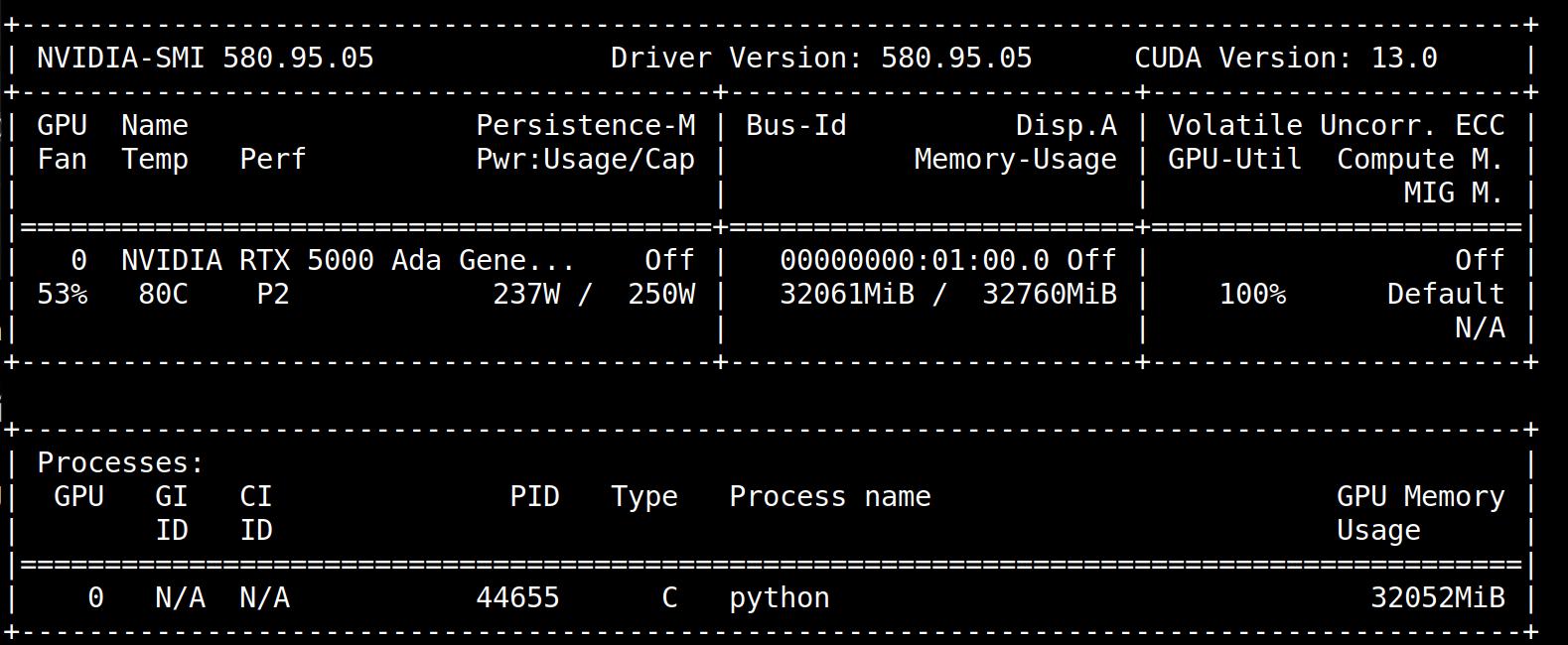
100% GPU utilisation! That’s what we like to see.
So after letting it cook away (it’s cold here, so I need the heat), and I then asked it: “What’s Superman’s height?”, and:
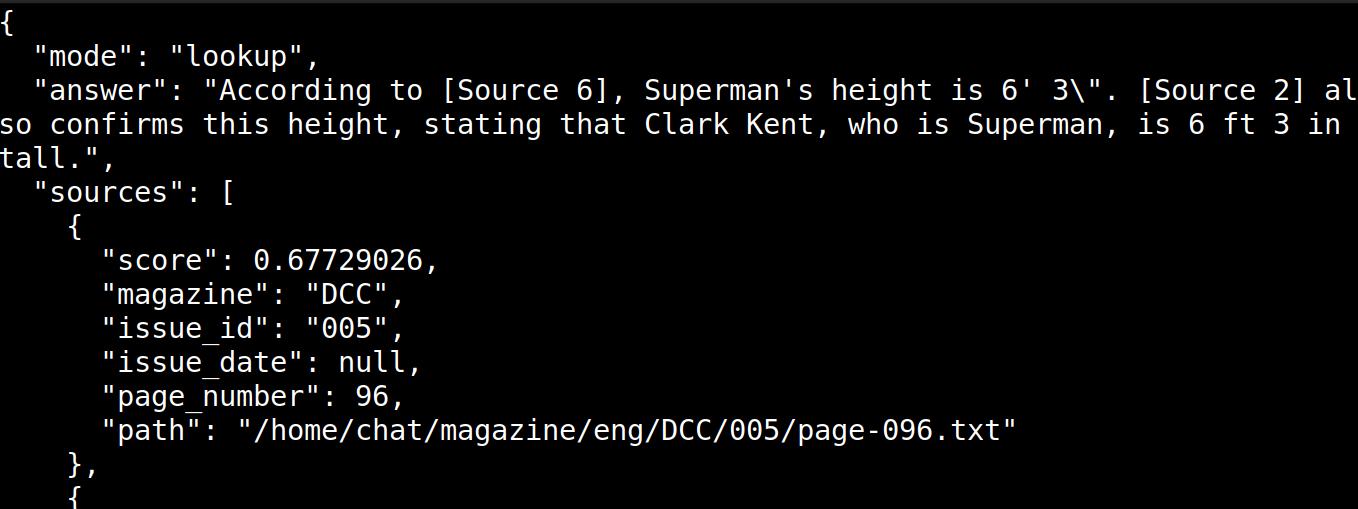
Wow! It works!
(For the technically minded: This is Qwen/Qwen2.5-7B-Instruct with Qdrant as the vector DB, the embedding model is BAAI/bge-m3, and the GPU is an RTX 5000 Ada.)
So I spent half an hour and made a web interface, and:
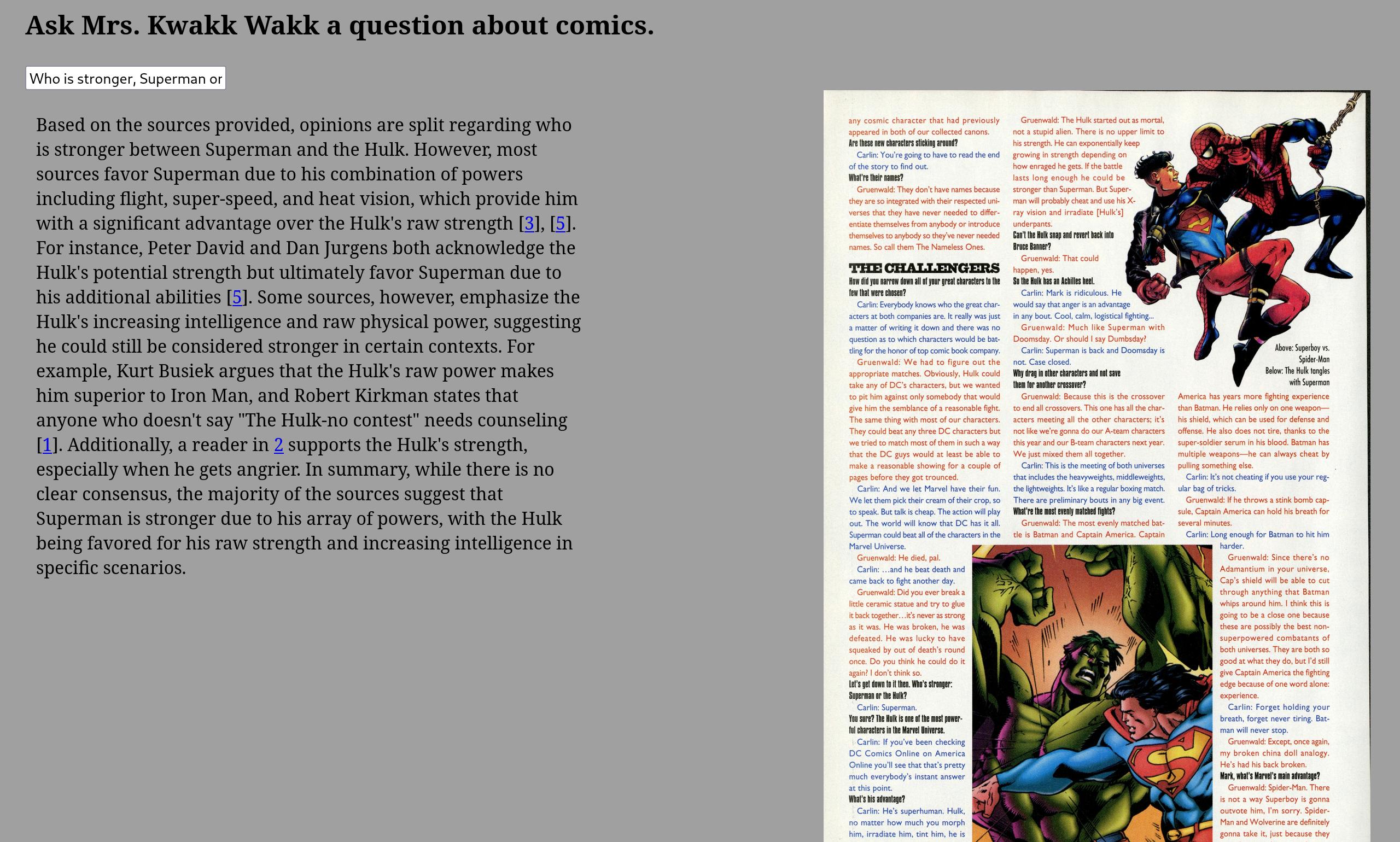
Opinions vary about who’s stronger of Hulk and Superman.
The LLM is set up to answer questions only based on what’s in this magazine/fanzine data set, to post references to its claims, and not give an answer if it doesn’t know.
But here’s the real test — something you can’t just search for, but need actual analysis to give an answer to: “What’s the beef between Harlan Ellison and Gary Groth”. Behold!

That answer is, of course, 100% nonsense, proving that this LLM works just as well as all other LLMs:
Additionally, [6] provides insight into the tension between Ellison and Groth, where Groth is criticized for editing the “Harlan Ellison Letters” section in a manner that Ellison found offensive, using derogatory terms like “gimp” and “feep.” Ellison felt that these terms were inappropriate and that Groth was unfairly targeting him.
Where’s that from?

Oh, it’s from a page that talks both about Harlan Ellison and John Byrne, who sounds like an asshole.
So there you go — an LLM trained on magazines and fanzines about comics. But I don’t think I’ll make a public interface for this — it takes about ten seconds to give an answer, and as you can see, the answers aren’t very good. I mean, it’s fine for simple questions:

But everybody knows that already, so…

First book written by J M DeMatteis?

Jack Kirby?
Well… OK… this does actually look kinda handy.

Actually, now I’m changing my mind! This is nice.

OK, I’m convinced! We’ve achieved general AI!?

It’s very modest…

I think… all of that is true?
Anyway. Setting this up was kinda fun, even if I’m never putting a public interface up for this thing.
Time to update my LinkedIn to say “AI Expert”.